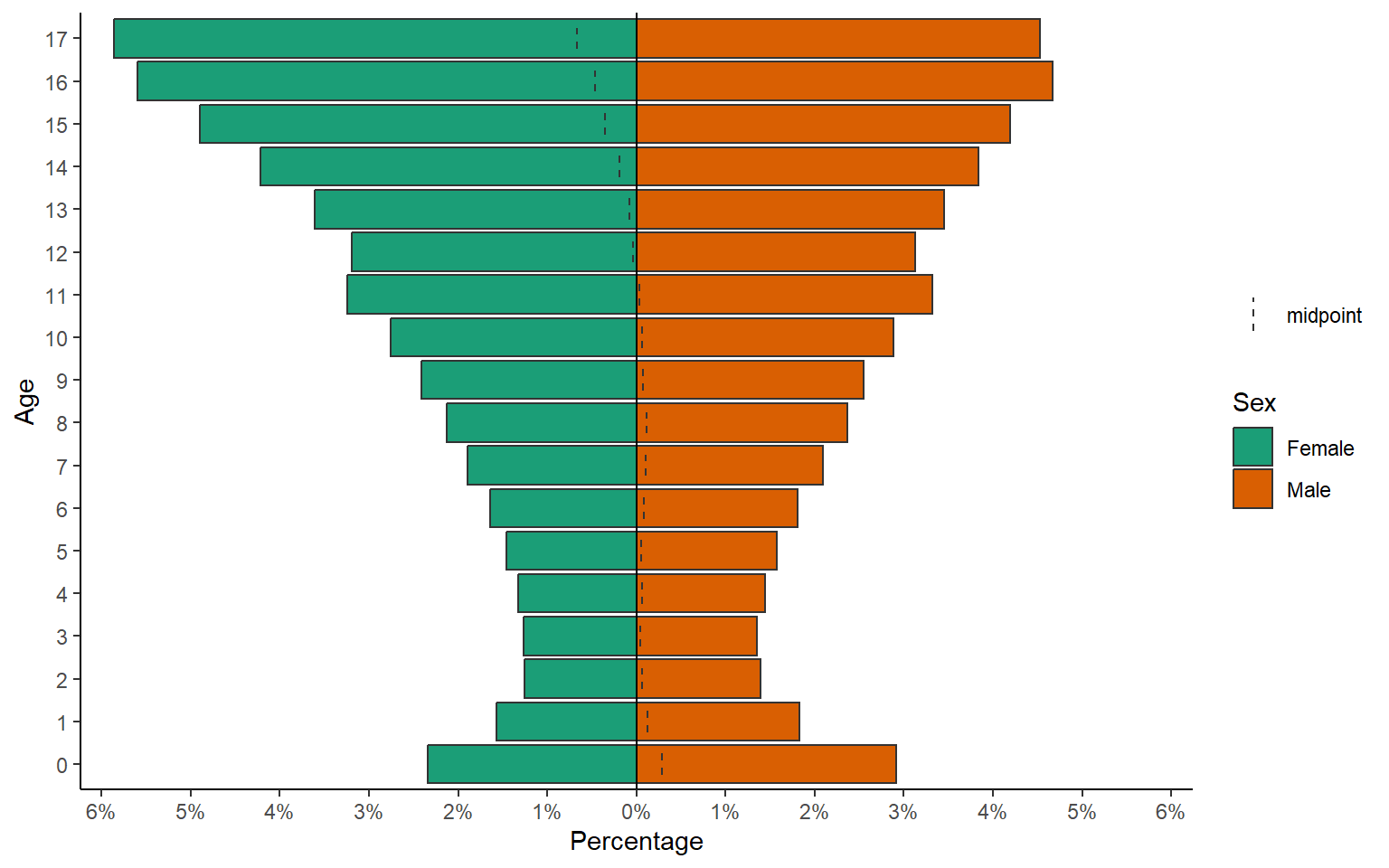
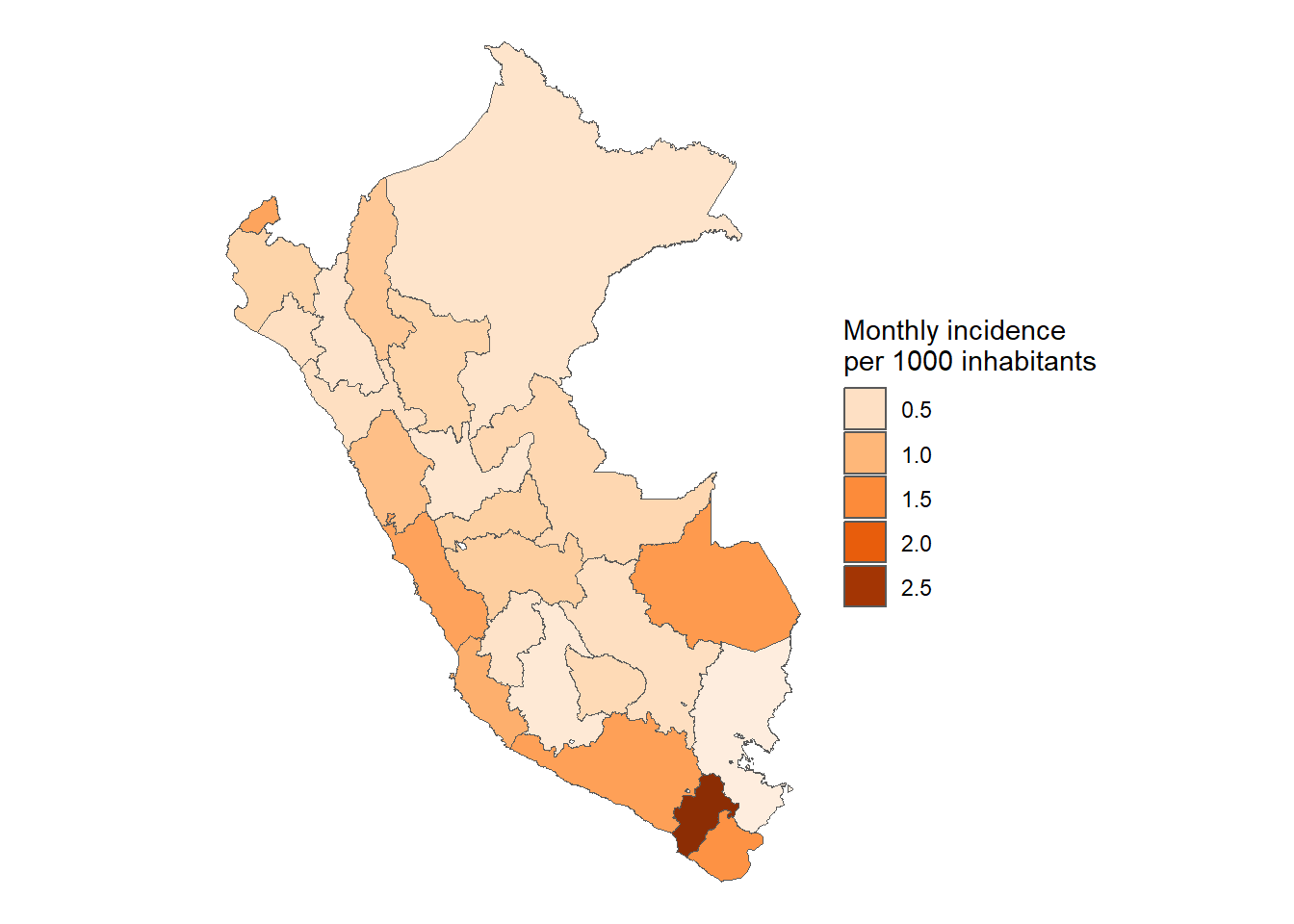
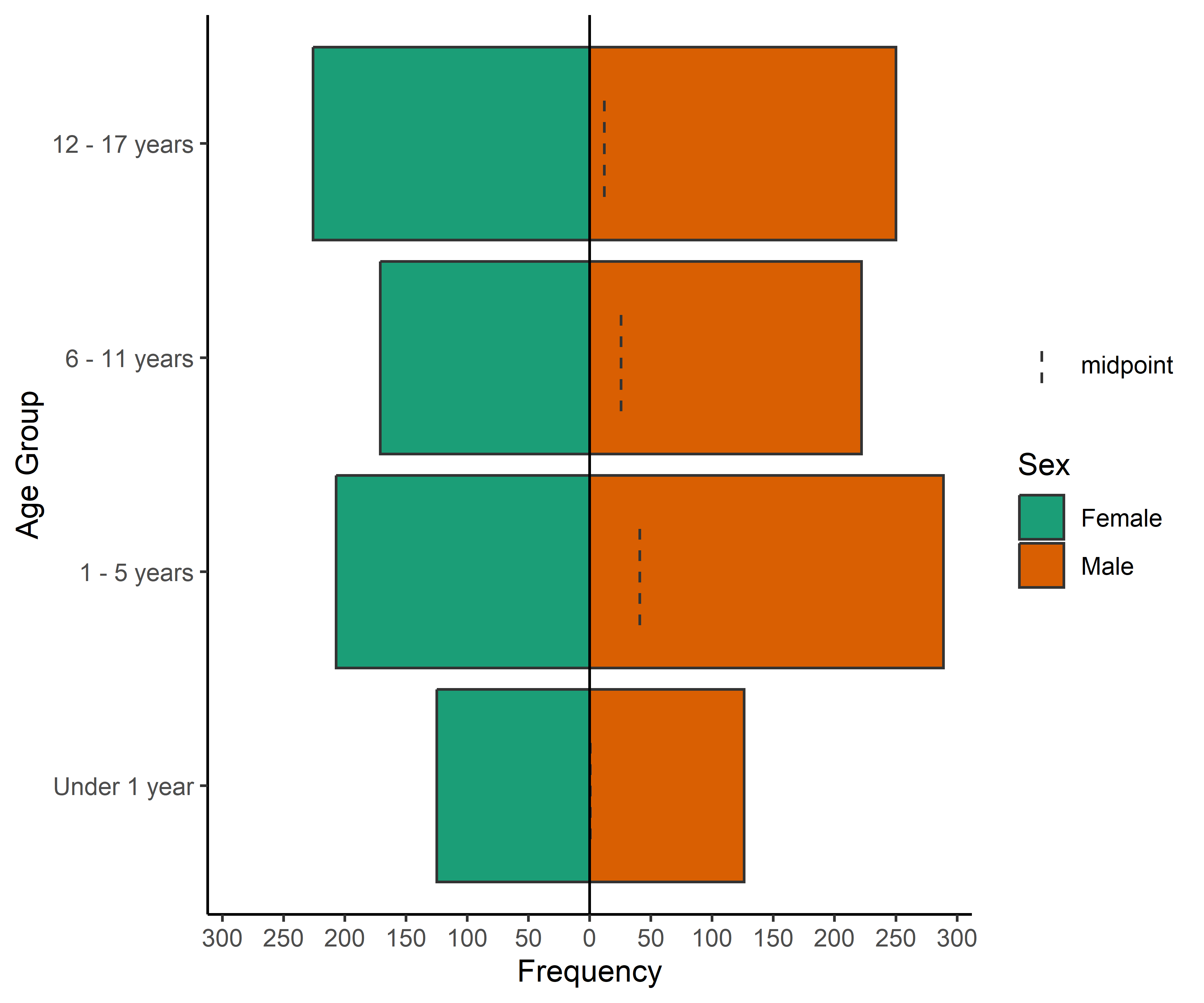
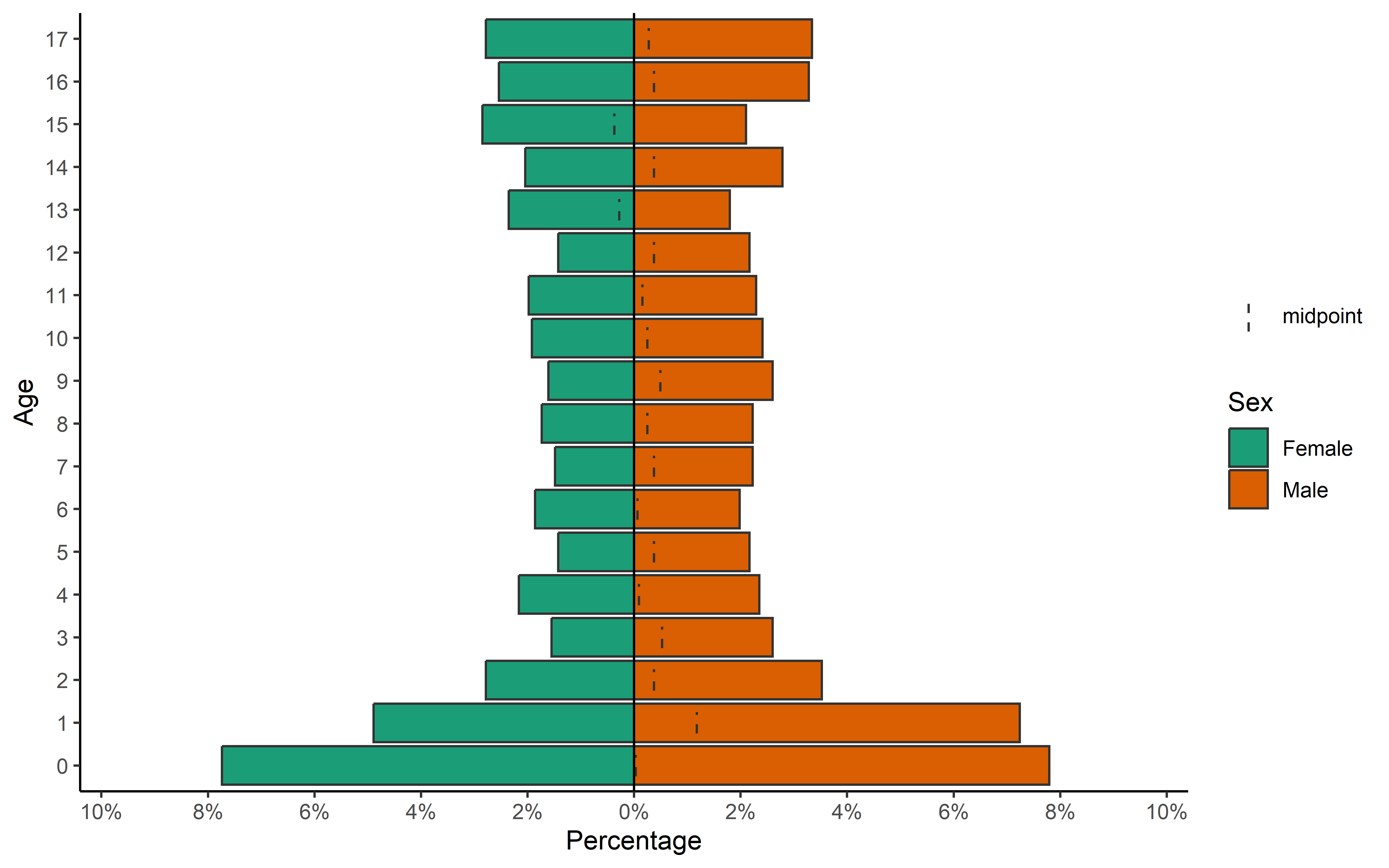
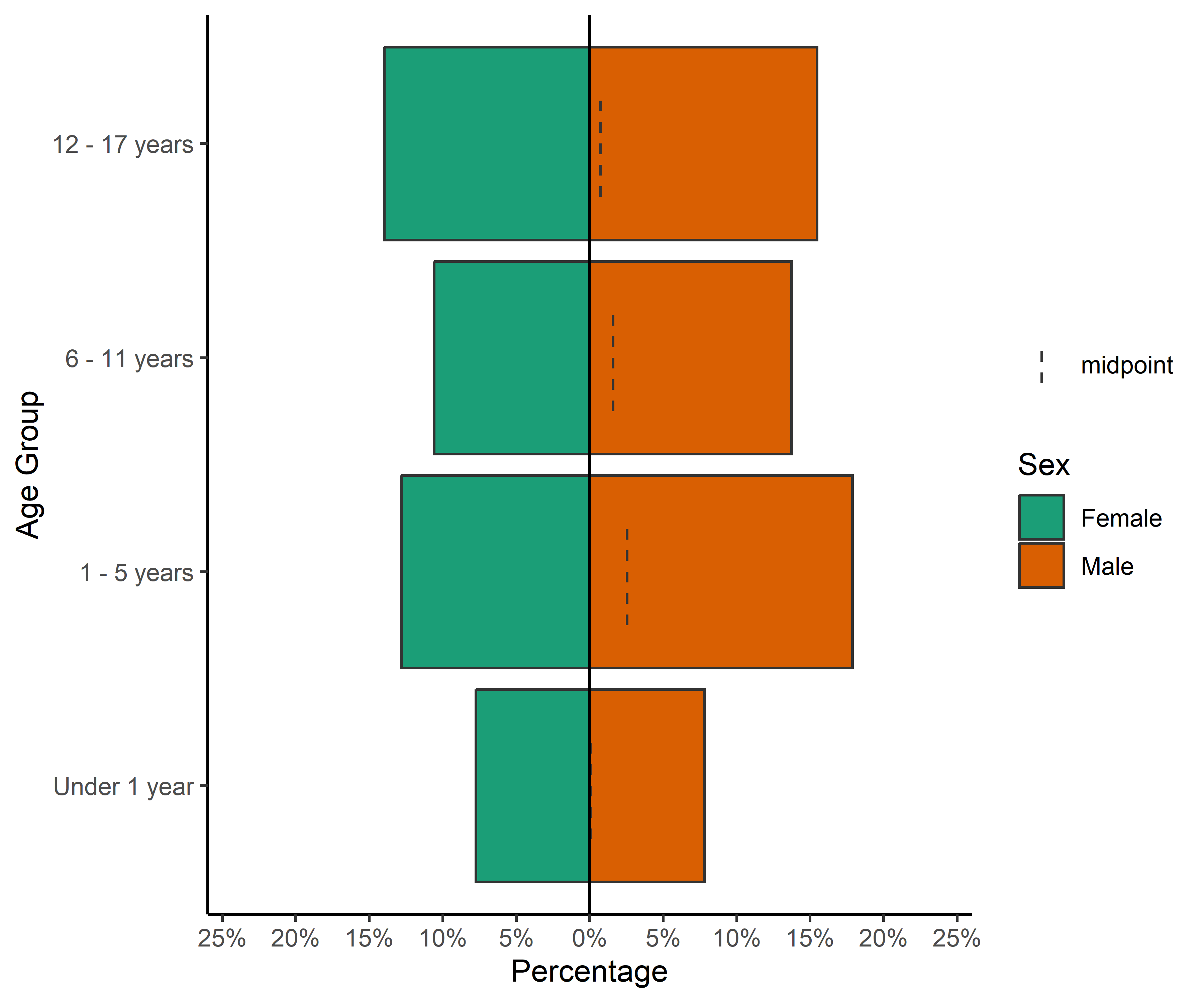
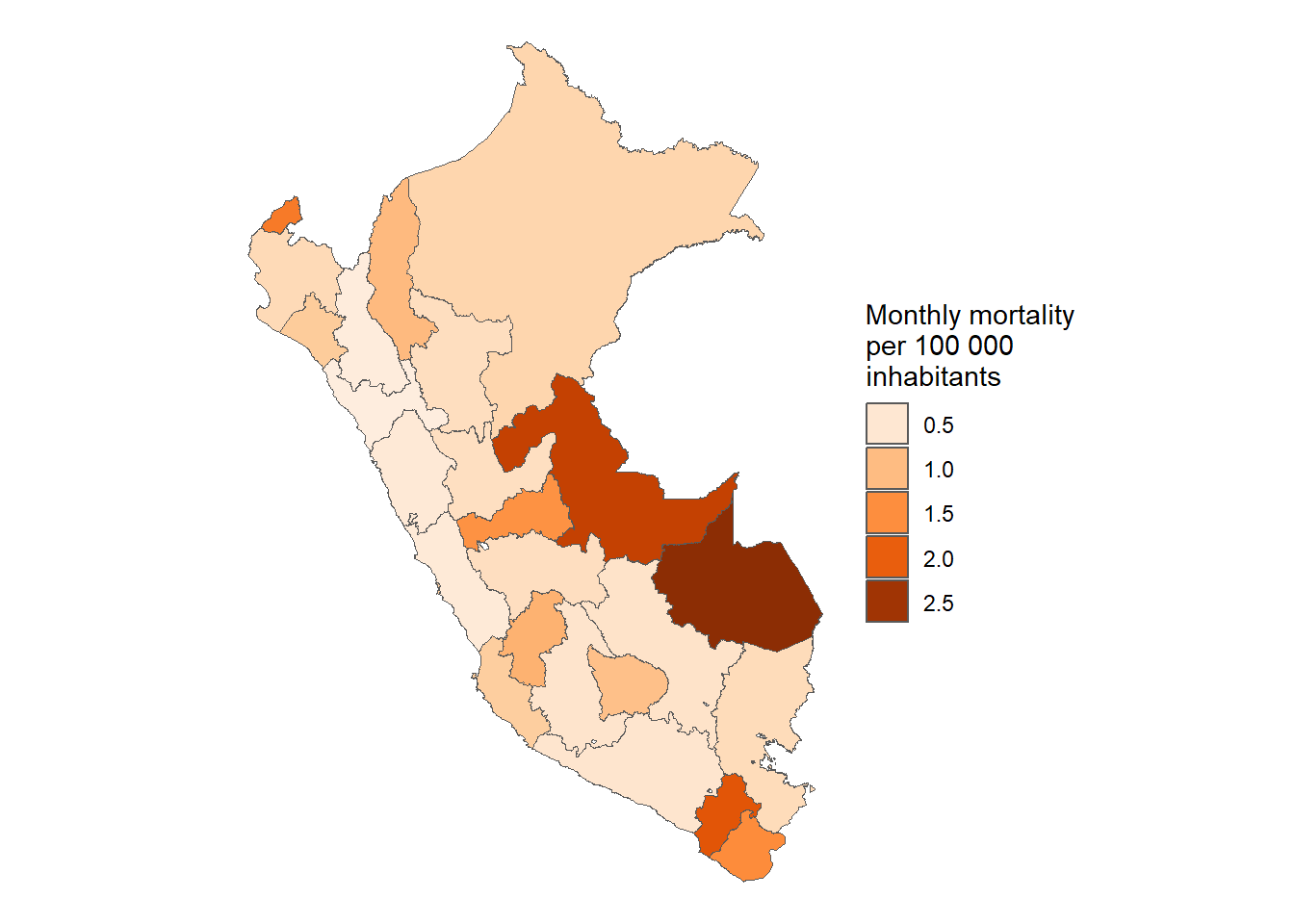
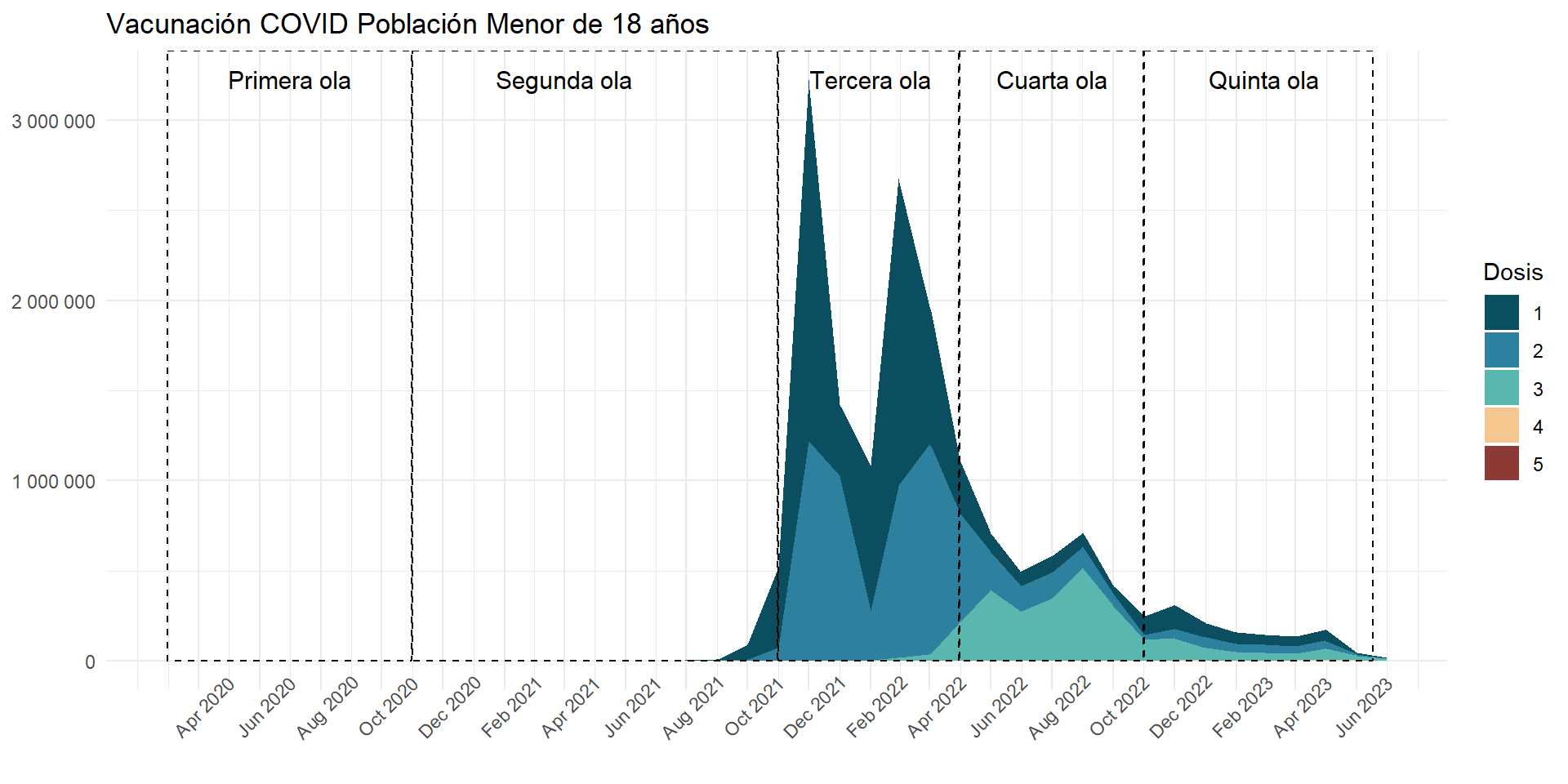
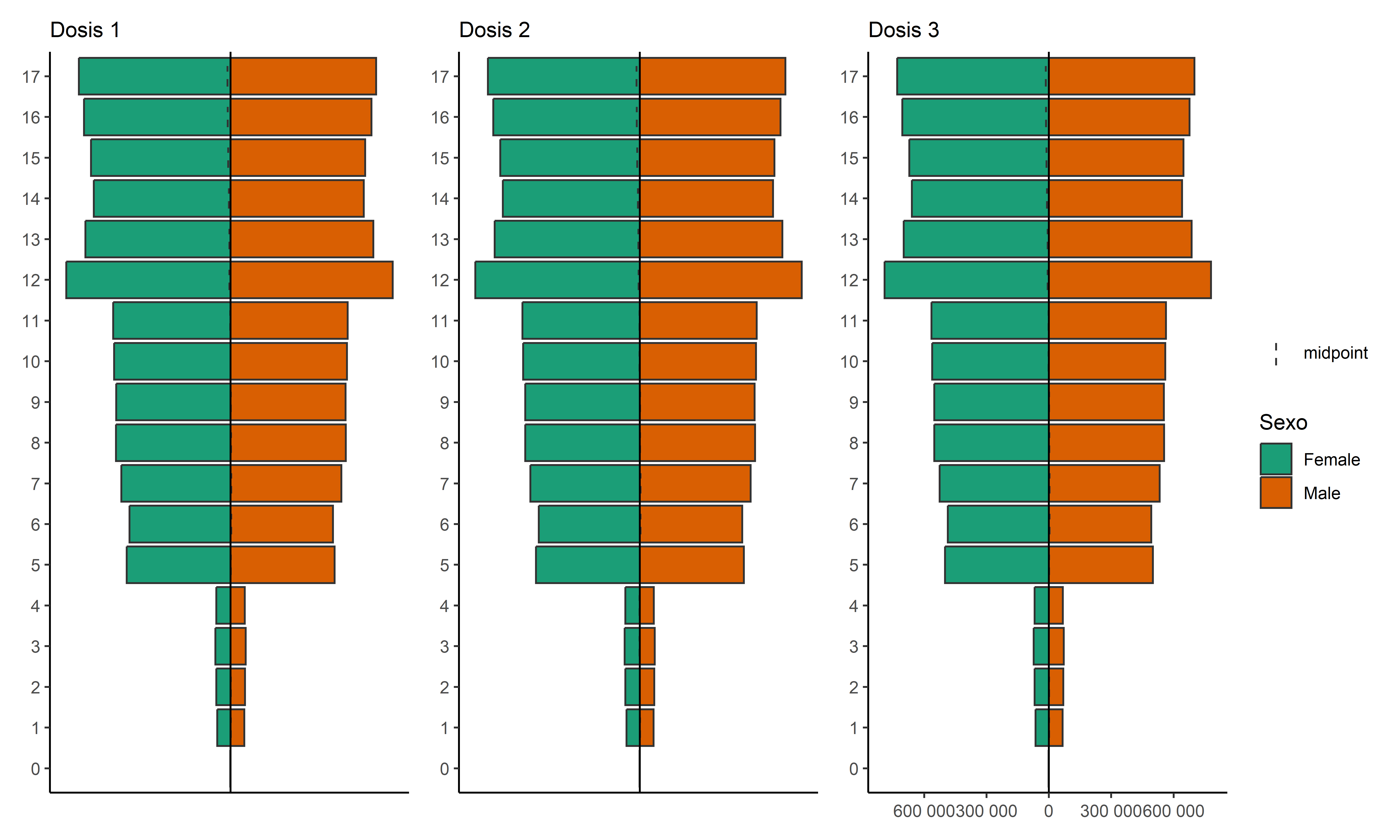
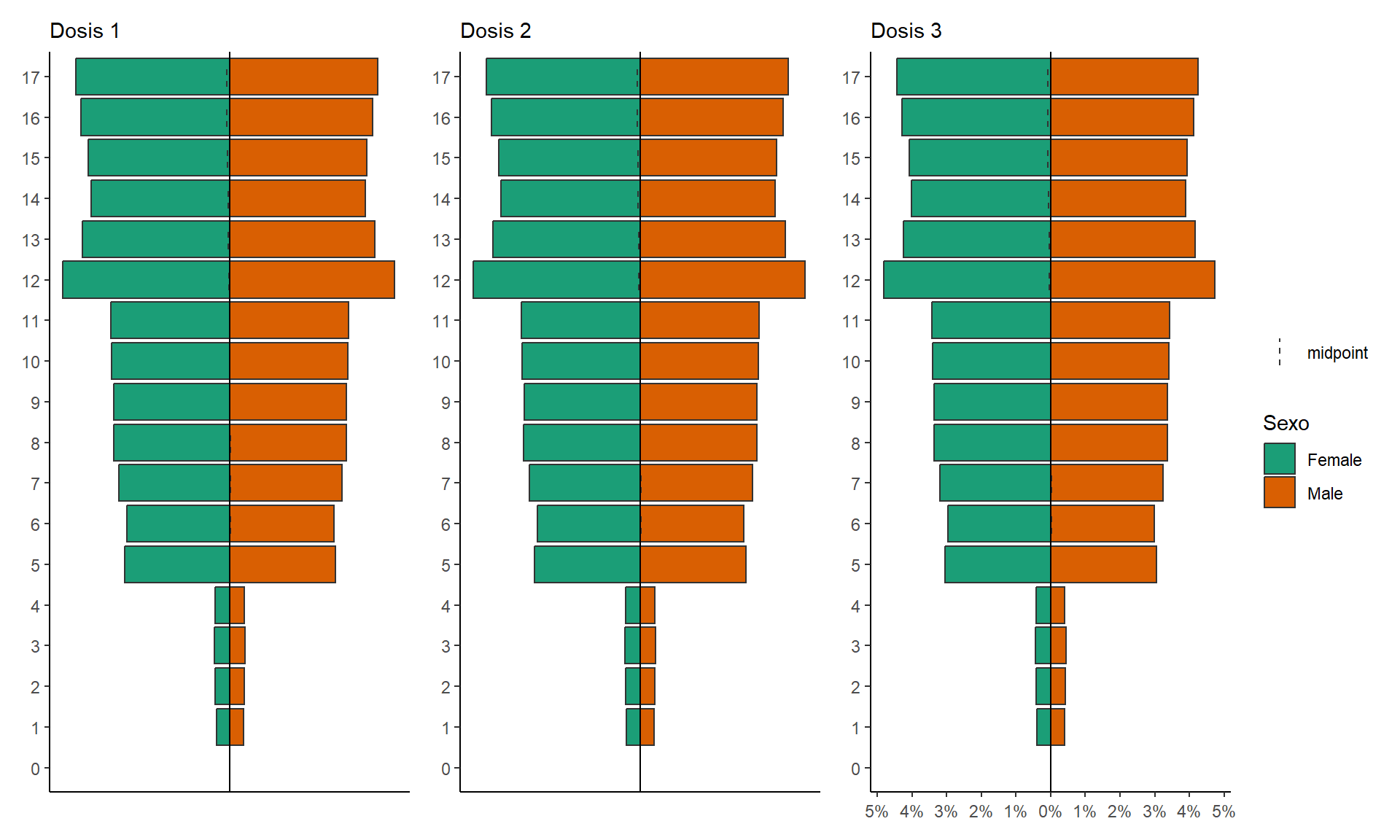
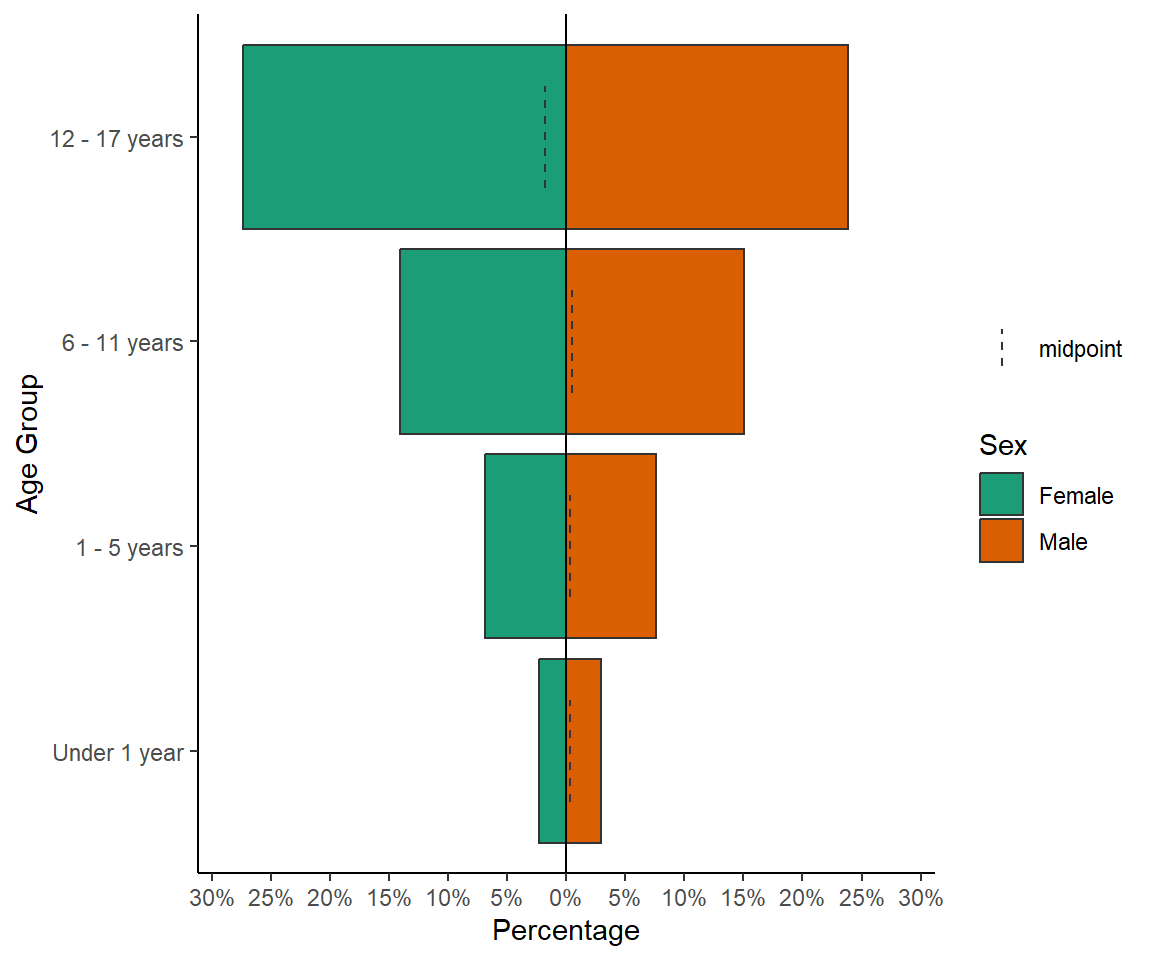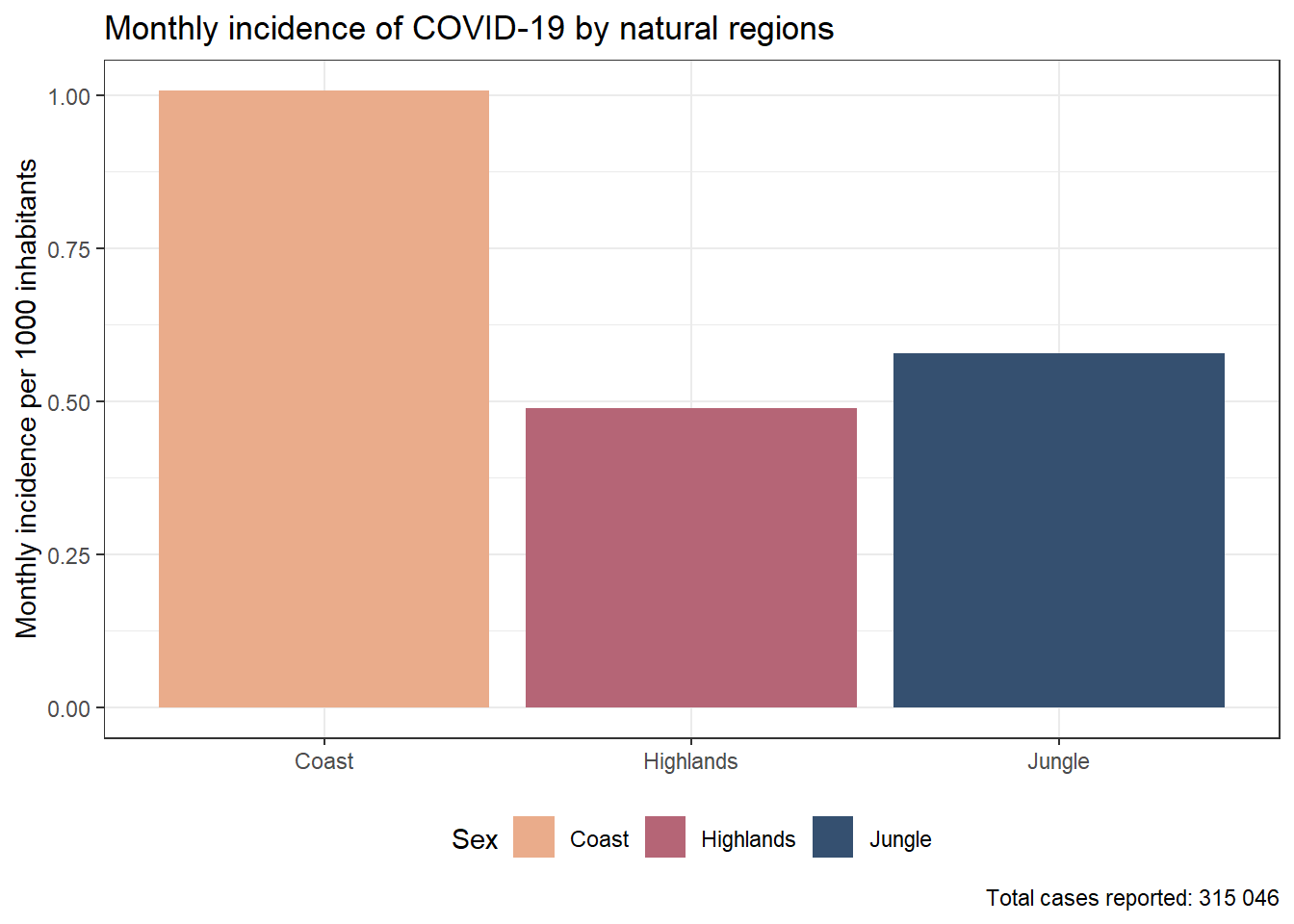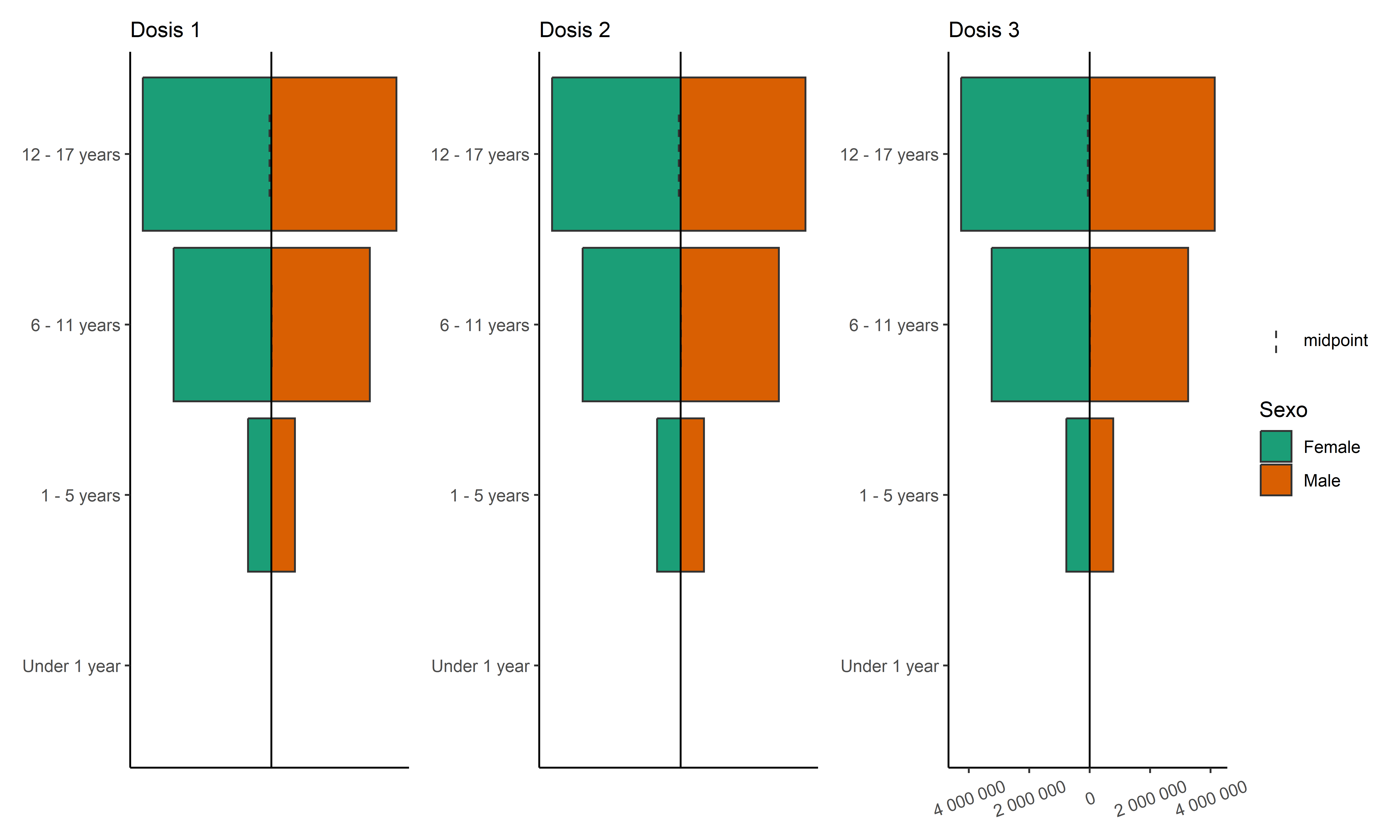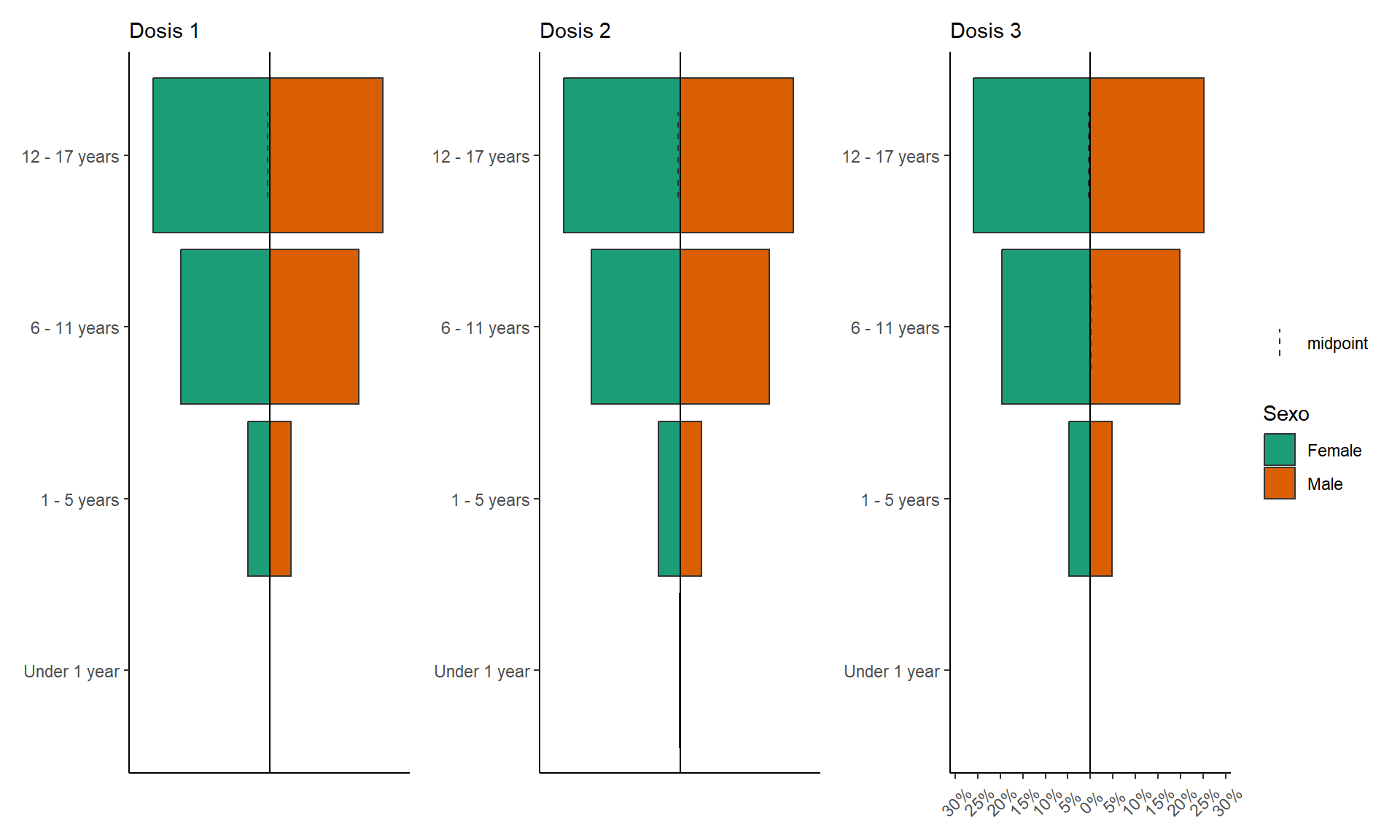COVID-19 en población pediátrica menor de 18 años según registros nacionales en Perú, 2020-2023
Autor/a
Afiliación
Brian Norman Peña-Calero
Laboratorio de Innovación en Salud - UPCH
Fecha de publicación
14 marzo, 2025
In [1]:
library(tidyverse)
Warning: package 'purrr' was built under R version 4.4.3
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(arrow)
Warning: package 'arrow' was built under R version 4.4.3
Adjuntando el paquete: 'arrow'
The following object is masked from 'package:lubridate':
duration
The following object is masked from 'package:utils':
timestamp
library(duckdb)
Warning: package 'duckdb' was built under R version 4.4.3
Cargando paquete requerido: DBI
library(dbplyr)
Adjuntando el paquete: 'dbplyr'
The following objects are masked from 'package:dplyr':
ident, sql
library(innovar)library(apyramid)library(sf)
Linking to GEOS 3.12.2, GDAL 3.9.3, PROJ 9.4.1; sf_use_s2() is TRUE
library(lmerTest)
Cargando paquete requerido: lme4
Cargando paquete requerido: Matrix
Adjuntando el paquete: 'Matrix'
The following objects are masked from 'package:tidyr':
expand, pack, unpack
Adjuntando el paquete: 'lmerTest'
The following object is masked from 'package:lme4':
lmer
The following object is masked from 'package:stats':
step
library(emmeans)
Warning: package 'emmeans' was built under R version 4.4.3
Welcome to emmeans.
Caution: You lose important information if you filter this package's results.
See '? untidy'
Warning: Missing values are always removed in SQL aggregation functions.
Use `na.rm = TRUE` to silence this warning
This warning is displayed once every 8 hours.
Joining with `by = join_by(ubigeo, dep, prov, distr)`
peru_dep_sf <- Peru %>%group_by(dep.code, dep) %>%summarise() %>%ungroup()
`summarise()` has grouped output by 'dep.code'. You can override using the
`.groups` argument.
peru_reg_sf <- Peru %>%group_by(region) %>%summarise() %>%ungroup()peru_macro_sf <- Peru %>%group_by(macrorregion) %>%summarise() %>%ungroup()
Actualmente los datos disponibles para el análisis tienen las siguientes situaciones:
Fallecidos COVID-19: Ahora mismo, esta data (Fallecidos por COVID-19 - [Ministerio de Salud - MINSA]) se encuentra actualizada en el portal de datos abiertos. Cuenta con 220 816 fallecidos que van desde 2020-03-03 al 2024-02-03.
Casos positivos COVID-19: Esta base de datos ya fue corregida y actualizada recientemente en la plataforma de datos abiertos. Cuenta con 4 548 255 casos positivos que van desde 2020-03-06 al 2023-12-31. Sin embargo, tiene el inconveniente de no tener registrado el id_persona que es indispensable para poder calcular los casos nuevos positivos COVID-19. Se usará por ahora una base actualizada a junio del 2023 con algunos casos menos, pero que si tiene esta información. El enlace de descarga de esa data desde el mismo Minsa ya no se encuentra disponible, pero si está en este repositorio Github: https://github.com/jmcastagnetto/covid-19-peru-limpiar-datos-minsa/tree/main/datos/originales
Hospitalizados por COVID-19: Esta data contiene a la vez información de la vacunación y fallecimiento de quienes fueron hospitalizados. Cuenta con 150 791 casos hospitalizados que van desde 2019-06-06 al 2024-01-03.
Vacunación COVID-19: Esta data contiene información de vacuna. Cuenta con 91 838 312 registros de vacunación que van desde 2020-04-27 al 2023-12-30.
Población Estimada: Esta data contiene las estimaciones poblacionales desde el 2020 al 2023 realizada por REUNIS. Presenta subdivisiones por distrito, edad y sexo. Sin embargo, la versión del año 2021, no tiene subdivisión por sexo, por lo que se usa la estimación realizada por el INEI que si lo contiene.
Para términos de uniformidad, temporalmente se restringirán todos los datos a junio de 2023.
Positivos - Prevalencia COVID-19
Para la estimación de la prevalencia, se obtuvo los datos poblacionales por distrito, sexo y grupo de edad para 2020, 2021, 2022 y 2023. A partir de ello, se calculó una prevalencia promedio mensual (Ecuación 1) que luego fue promediada para obtener un único valor por distrito, sexo y grupo de edad. Finalmente, se reporta la prevalencia promedio mensual por 1000 habitantes en anualidades (Ecuación 2) u olas covid, a fin de tener una lectura con menor términos decimales.
\[
\text{Prevalencia promedio mensual}_i = \frac{\text{Promedio de Número de casos en el mes del año } i}{\text{Población en el año } i}
\tag{1}\]
Donde:
\(\text{Número de casos en el año } i\) es el número de positivos COVID-19 en un año en específico (2020-2023)
\(\text{Población en el año } i\) es la población que puede ser afectada por COVID-19 en un año en específico (2020-2023)
\[
\text{Prevalencia Promedio mensual por 1000 habitantes} = \left( \frac{\sum_{i=2020}^{2023} \text{Prevalencia promedio mensual}_i}{\text{Número de Años}} \right) \times 1000
\tag{2}\]
downloadthis::download_file(path ="02_output/tables/positivos_descriptivos.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [11]:
downloadthis::download_file(path ="02_output/tables/positivos_descriptivos.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
In [12]:
comparing_levels <-list(c("grupo_edad"),c("sexo"),c("ola_covid"),c("cuartil_pobreza"),c("cuartil_nbi"),c("region"),c("macrorregion"))prevalence_comparisons <-compare_levels_per_month(results_per_month = results_per_month_prevalencia,levels = comparing_levels)# Extraer las tablas `cld` como tibbles, renombrando y añadiendo una columna "level"prevalence_comparisons_cld_pre <-lapply(names(prevalence_comparisons), function(level) { cld <- prevalence_comparisons[[level]]$cldif (!is.null(cld)) { cld <- cld |>as_tibble() |>rename(group =1) |># Renombra la primera columna a 'group'mutate(level = level) |># Añade una columna 'level' con el nombre de la listarelocate(level) } cld}) |>bind_rows()prevalence_comparisons_cld_pre <- prevalence_comparisons_cld_pre |>mutate(across(where(is.numeric),~ formattable::digits(.x, 3) ) )
downloadthis::download_file(path ="02_output/tables/prevalencia_comparacion_multiple.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [17]:
downloadthis::download_file(path ="02_output/tables/prevalencia_comparacion_multiple.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/positivos_olas_descriptivos.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [22]:
downloadthis::download_file(path ="02_output/tables/positivos_olas_descriptivos.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
Gráfico de positivos (serie de tiempo) - Menores de 18 años
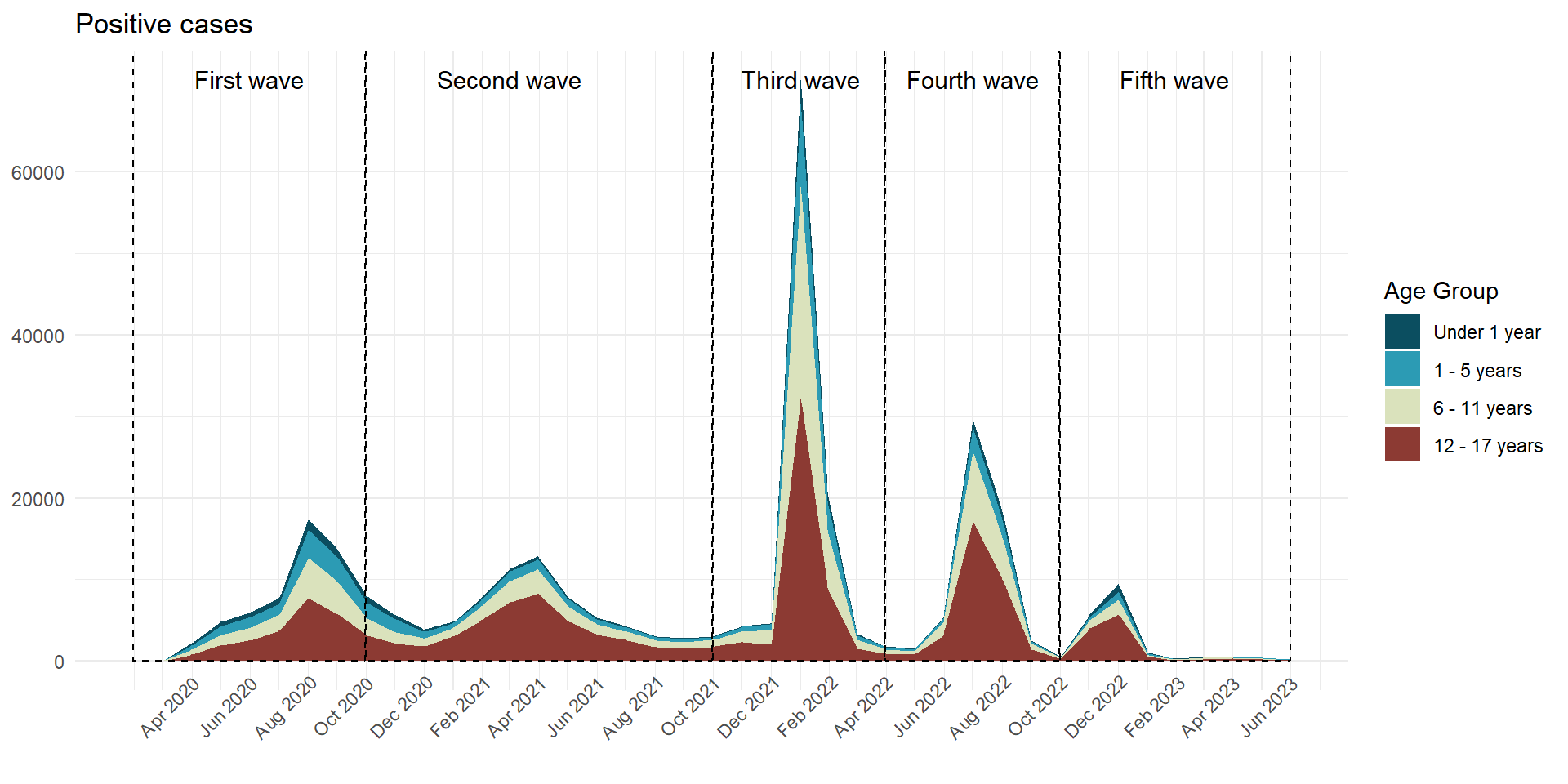
positive_cases_area <- positivos_0723 %>%mutate(fecha_round =case_when( fecha_round ==as.Date("2024-01-01") ~as.Date("2023-12-31"),.default = fecha_round ) ) %>%count(grupo_edad, fecha_round) %>%collect() %>%ggplot(aes(x = fecha_round,y = n,fill = grupo_edad ) ) +geom_area(position ='stack') +# innovar::scale_fill_innova("jama") +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#DAE2BC", "#8C3A33") ) +scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +labs(y =NULL,x =NULL,title ="COVID-19 cases",fill ="Age Group" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =as.Date("2023-07-01"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"),y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() ) positive_cases_area
Warning: Removed 4 rows containing non-finite outside the scale range
(`stat_align()`).
Figura 1: Positividad COVID Población menor de edad de acuerdo al grupo de edad y ola (07-03-2020 a 17-06-2023)
Gráfico de Incidencia (serie de tiempo) - Menores de 18 años
In [24]:
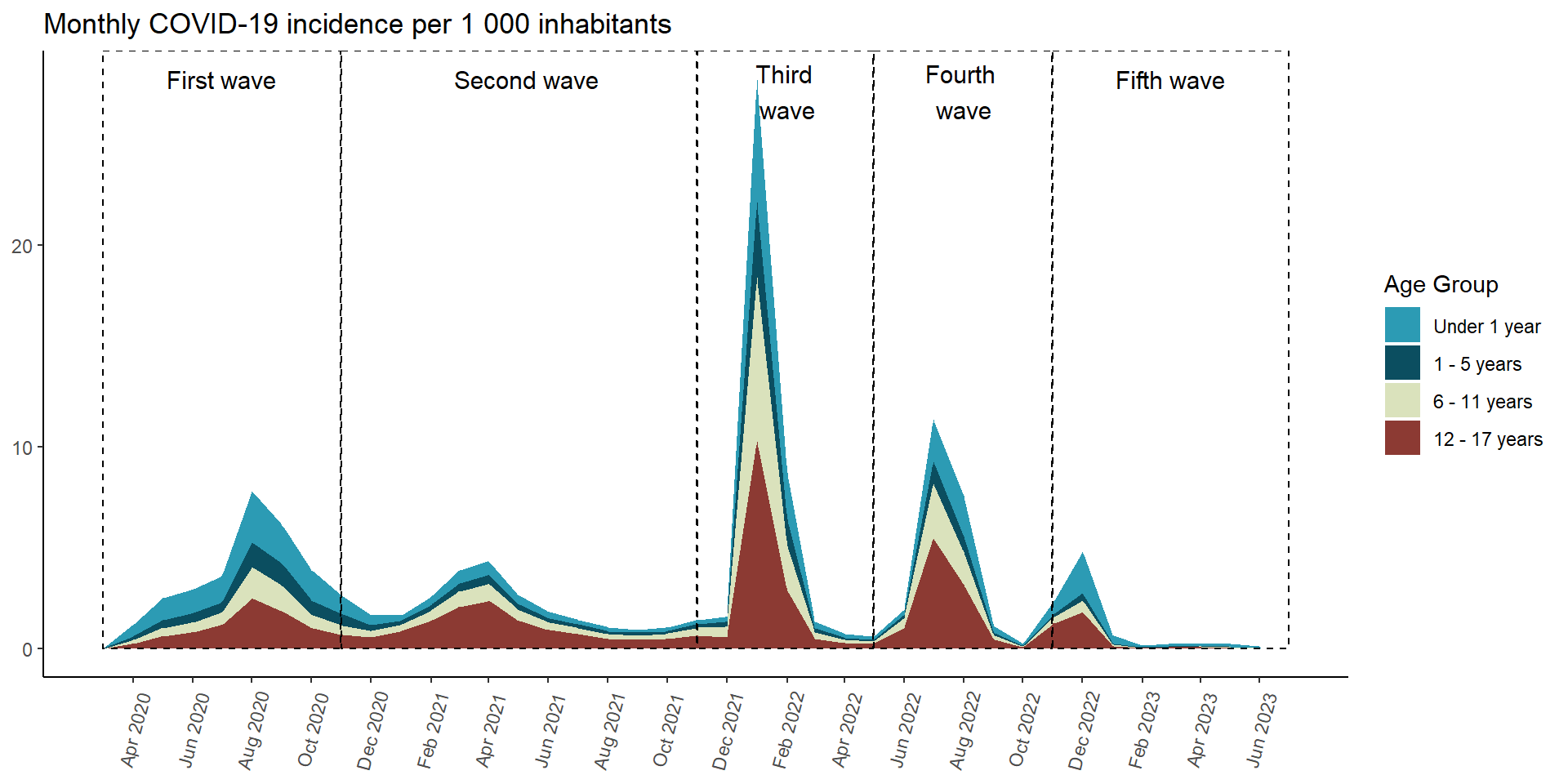
prevalence_by_age_area <- results_per_month_prevalencia$grupo_edad$index %>%mutate(time =make_date(anio, mes, "1") ) %>%ggplot(aes(x = time,y = rate,fill = grupo_edad ) ) +geom_area(position ='stack') +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#DAE2BC", "#8C3A33") ) +scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +labs(y =NULL,x =NULL,title ="Monthly COVID-19 incidence per 1 000 inhabitants",fill ="Age Group" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =as.Date("2023-07-01"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"),y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() ) prevalence_by_age_area
Warning: Removed 4 rows containing non-finite outside the scale range
(`stat_align()`).
Figura 2: Incidencia COVID Población menor de edad de acuerdo al grupo de edad y ola (07-03-2020 a 17-06-2023)
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
downloadthis::download_file(path ="02_output/tables/prevalencia_departamento.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [35]:
downloadthis::download_file(path ="02_output/tables/prevalencia_departamento.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
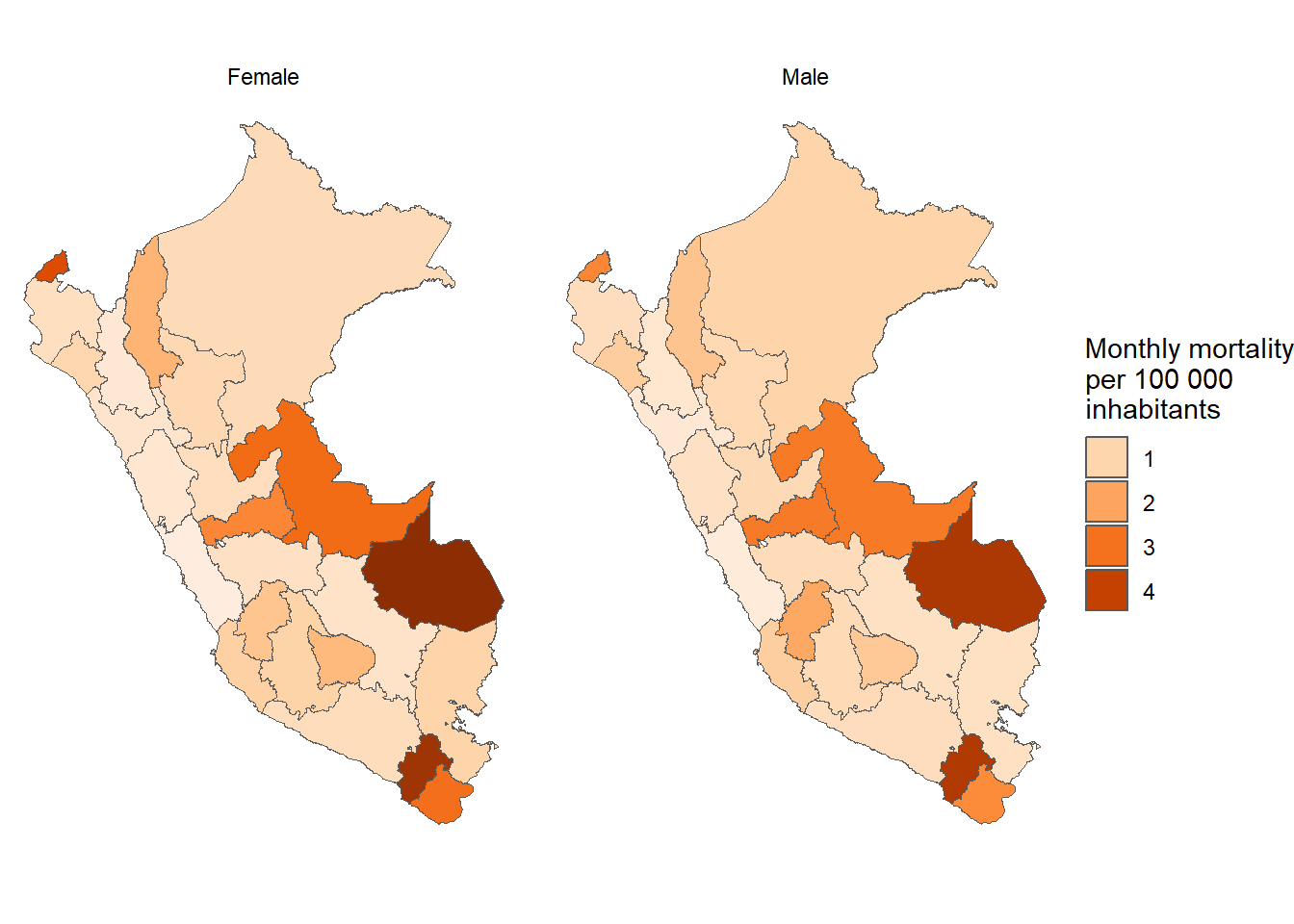
Departamento y sexo
In [36]:
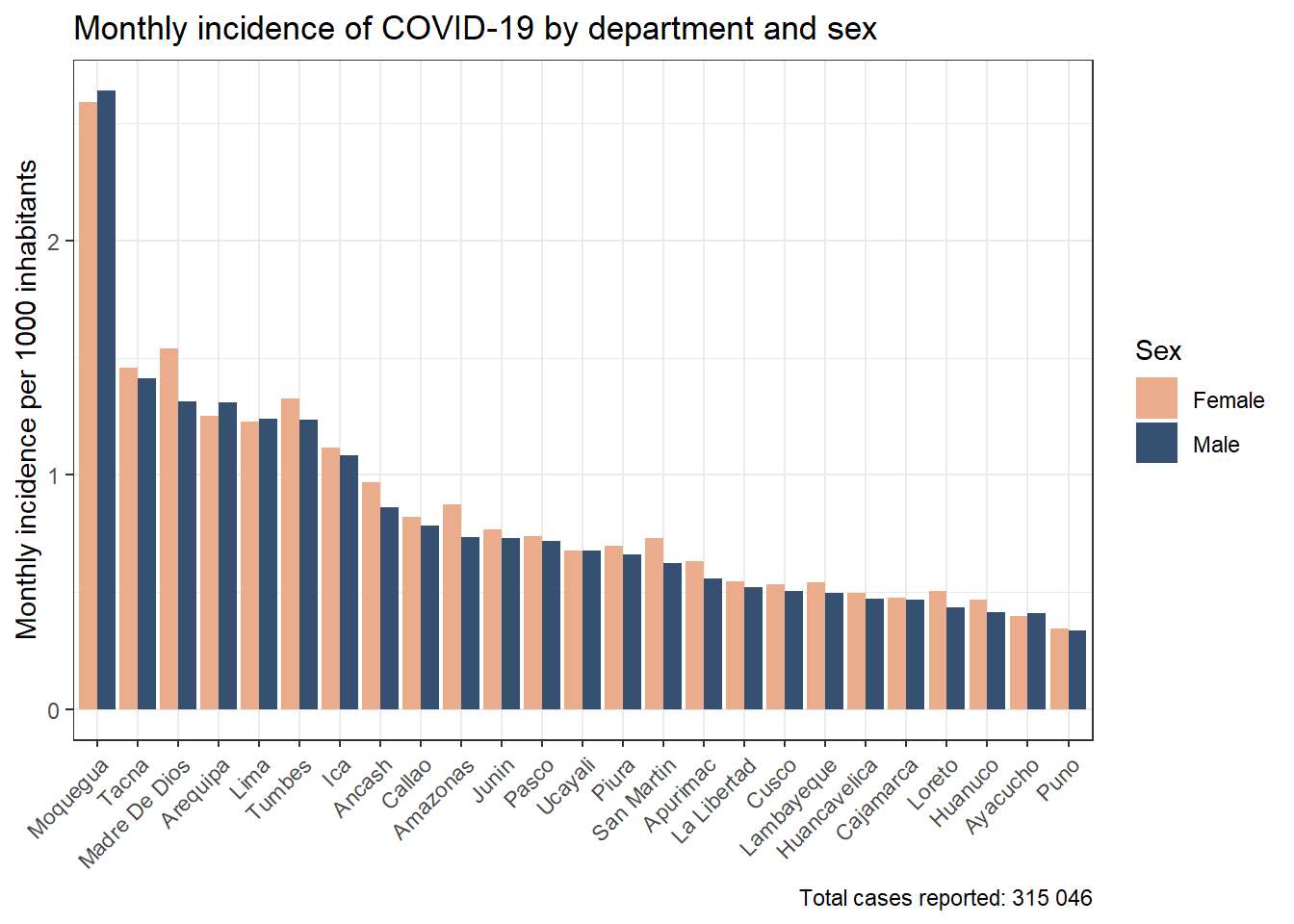
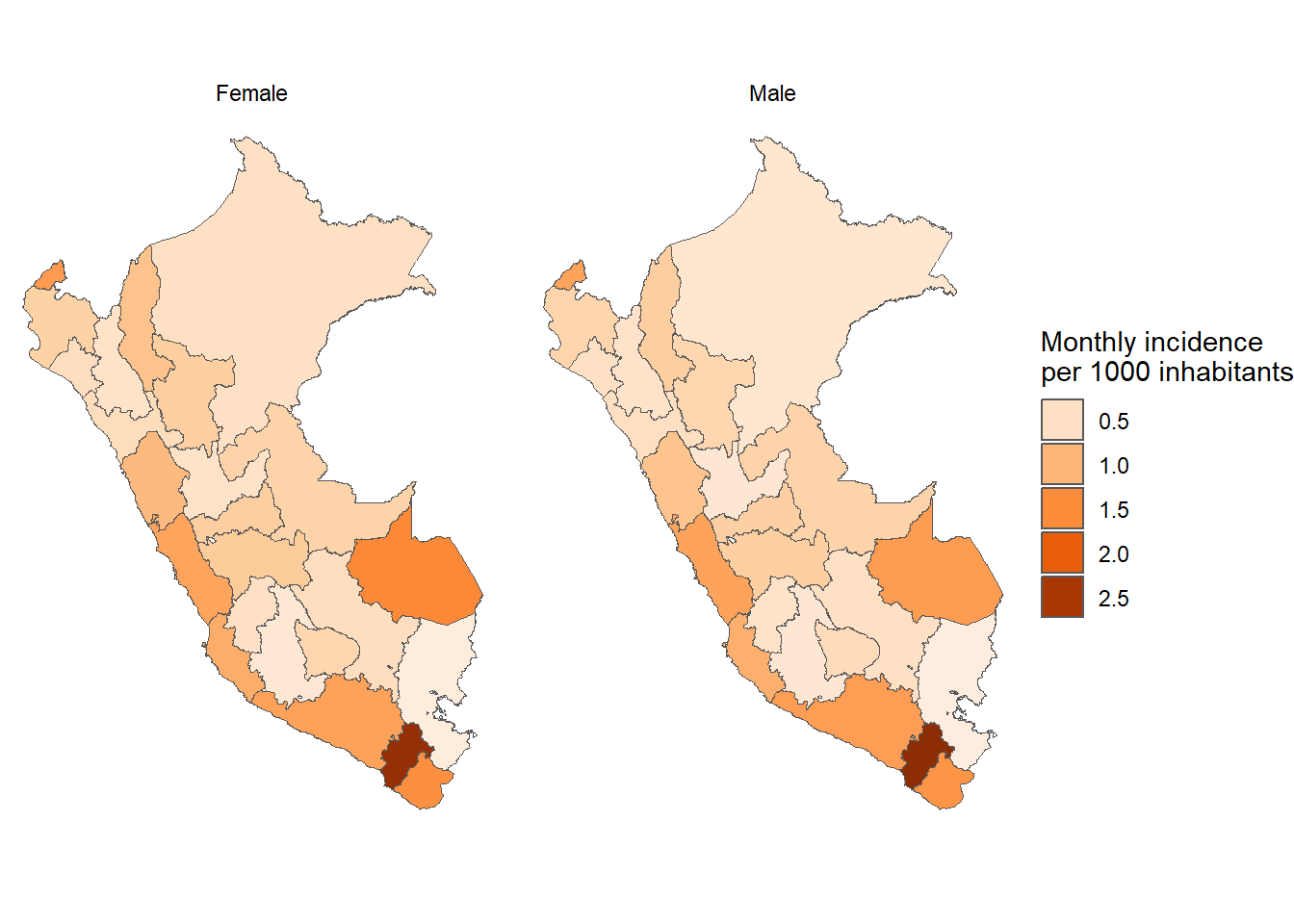
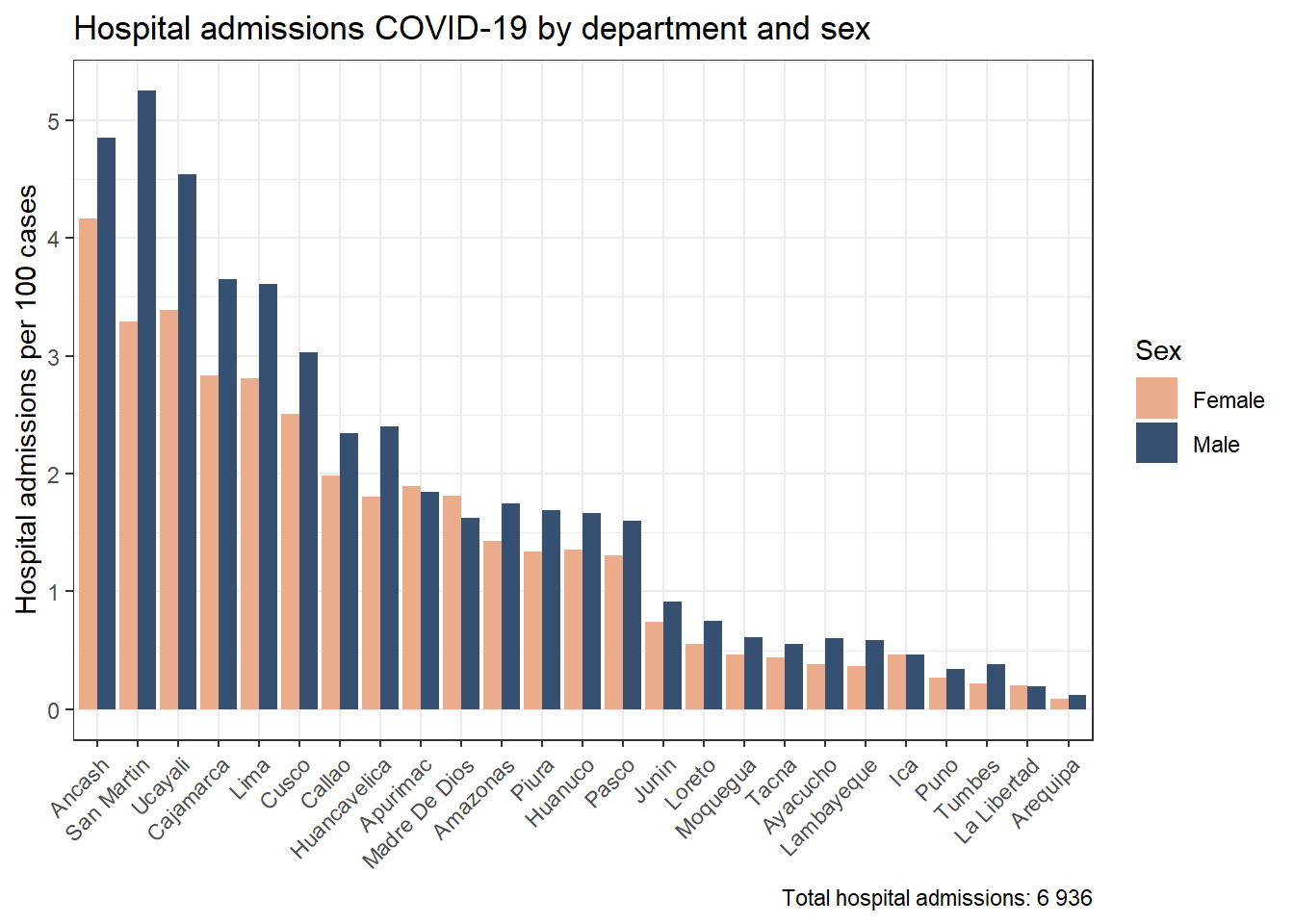
results_prevalencia$departamento_sexo$index %>%mutate(departamento =str_to_title(departamento),departamento =fct_reorder2(departamento, sexo, rate) ) %>%ggplot(aes(x = departamento, y = rate, fill = sexo)) +geom_bar(stat ="identity", position =position_dodge()) +theme_bw() +labs(title ="Monthly incidence of COVID-19 by department and sex", x =NULL, y ="Mean monthly COVID-19 incidence",fill ="Sex",caption =paste0("Total cases reported: ", scales::number(sum(pull(results_prevalencia$departamento_sexo$index_pre, count))))) + innovar::scale_fill_innova("blue_fall") +theme(axis.text.x =element_text(angle =45,hjust =1,vjust =1 ) )
Figura 4: Prevalencia COVID-19 de acuerdo al departamento y sexo (07-03-2020 a 17-06-2023)
downloadthis::download_file(path ="02_output/tables/prevalencia_departamento_sexo.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [43]:
downloadthis::download_file(path ="02_output/tables/prevalencia_departamento_sexo.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
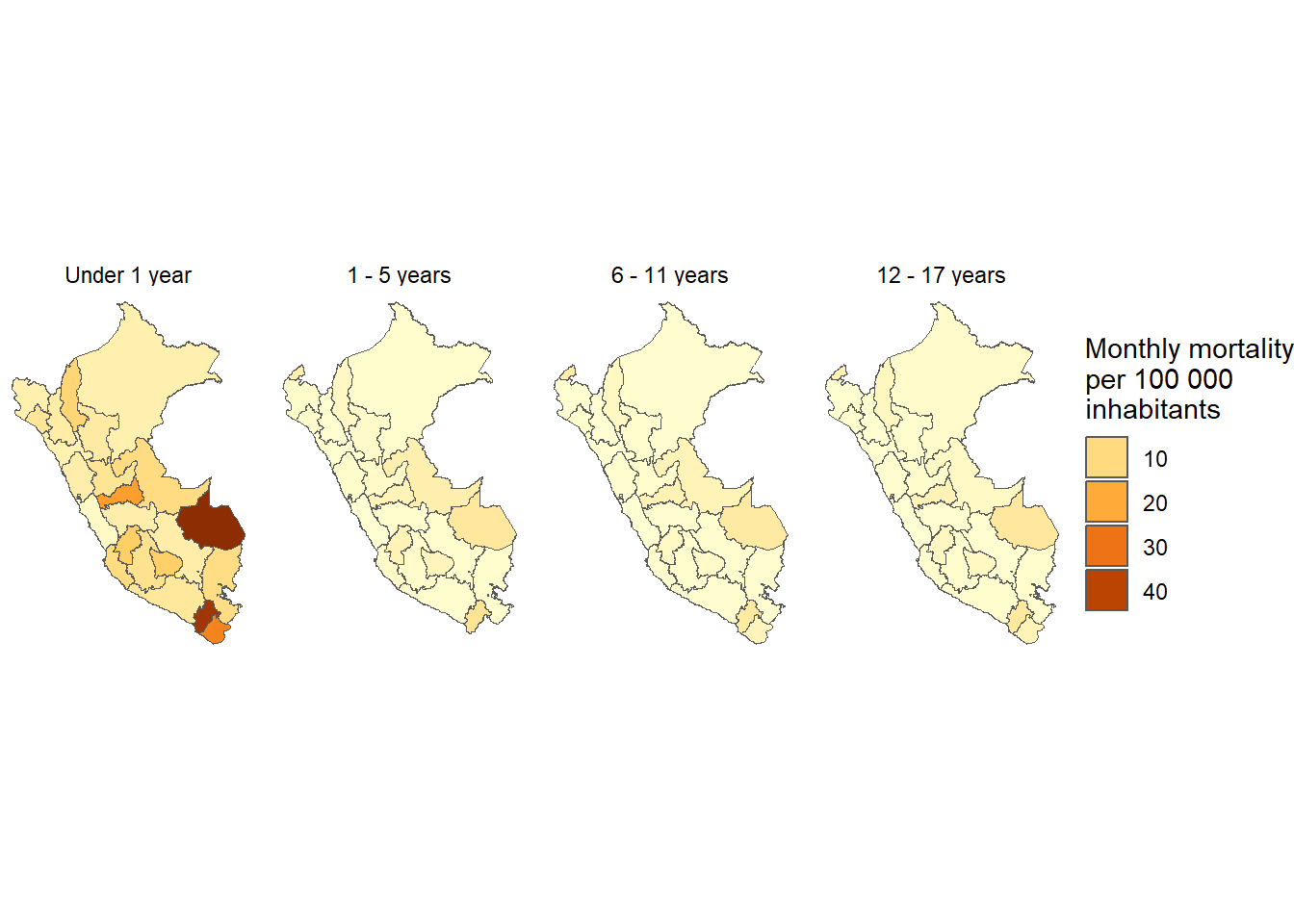
Departamento y edad
In [44]:
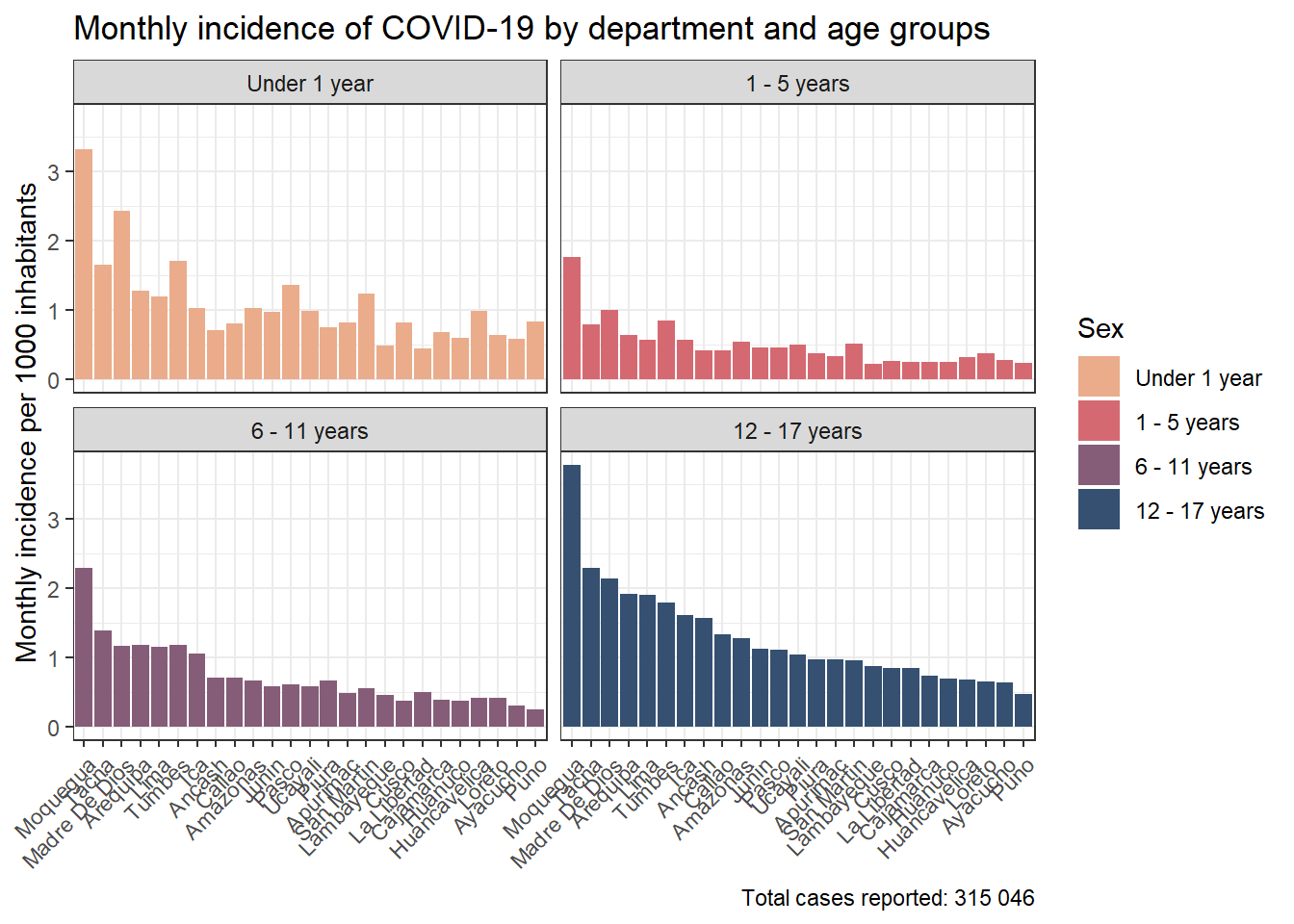
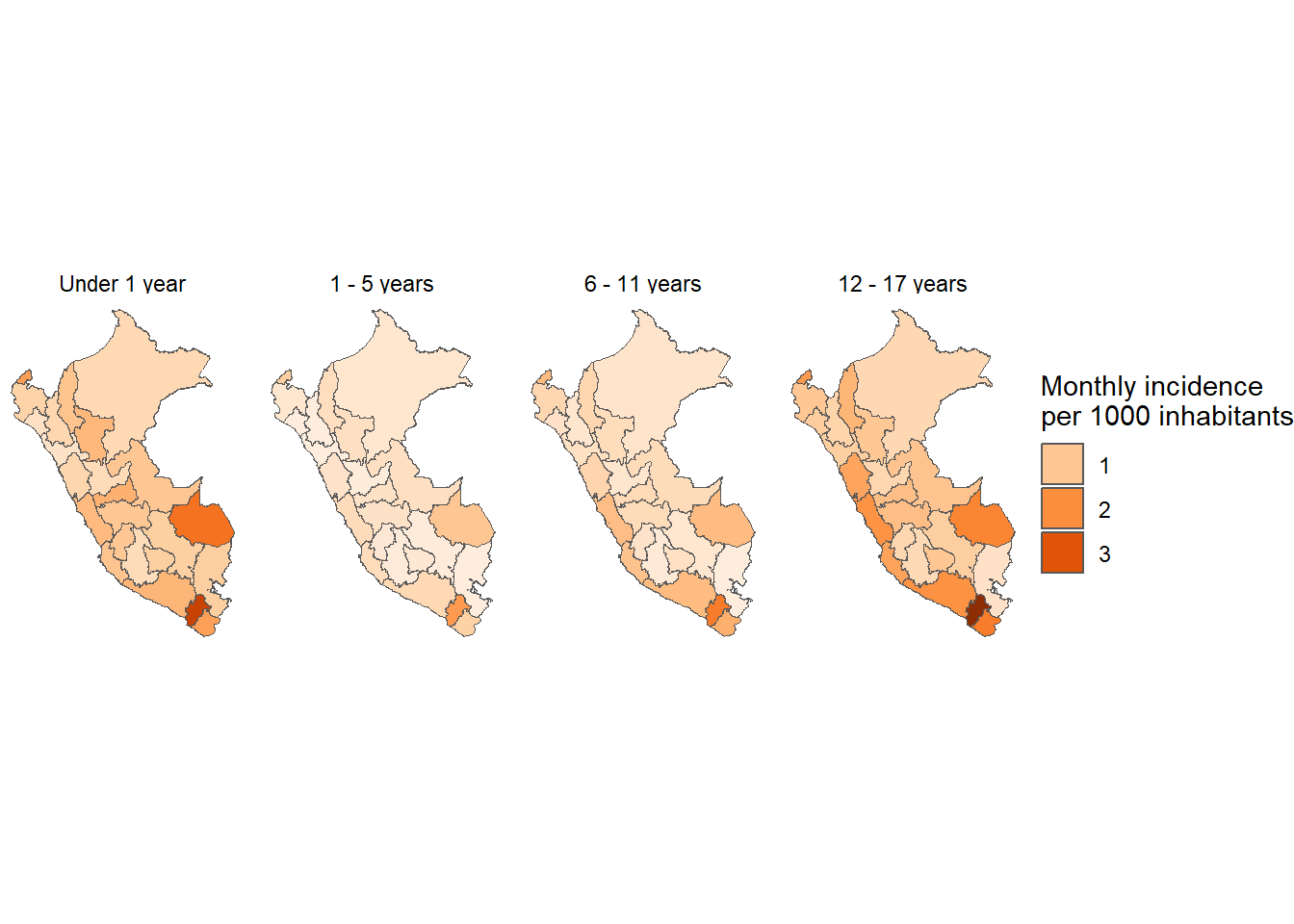
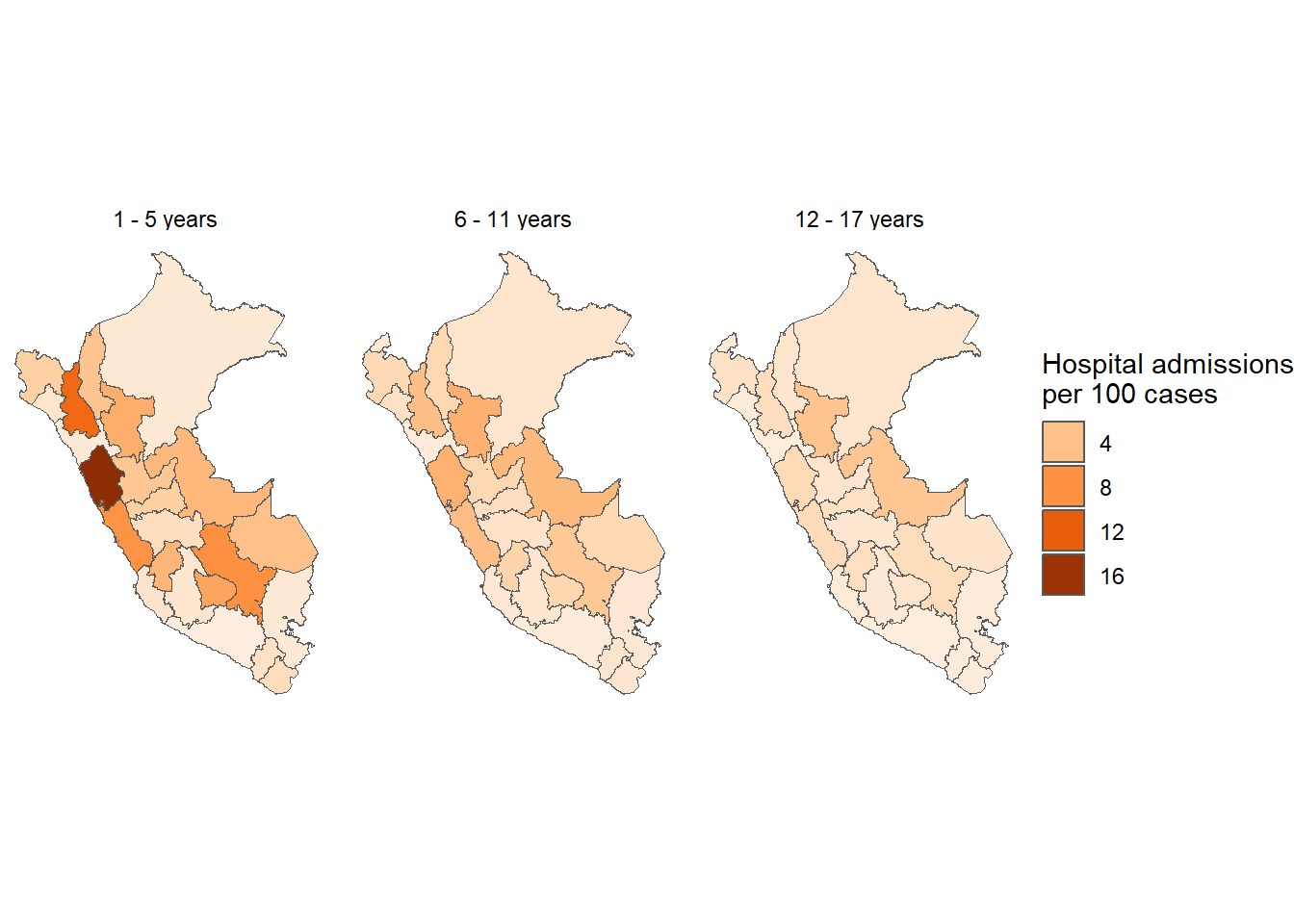
results_prevalencia$departamento_grupo_edad$index %>%mutate(departamento =str_to_title(departamento),departamento =fct_reorder2(departamento, grupo_edad, rate) ) %>%ggplot(aes(x = departamento, y = rate, fill = grupo_edad)) +geom_bar(stat ="identity") +theme_bw() +labs(title ="Monthly incidence of COVID-19 by department and age groups", x =NULL, y ="Mean monthly COVID-19 incidence",fill ="Sex",caption =paste0("Total cases reported: ", scales::number(sum(pull(results_prevalencia$departamento_grupo_edad$index_pre, count))))) + innovar::scale_fill_innova("blue_fall") +facet_wrap(vars(grupo_edad)) +theme(axis.text.x =element_text(angle =45,hjust =1,vjust =1 ) )
Figura 6: Prevalencia COVID-19 de acuerdo al departamento y edad (07-03-2020 a 17-06-2023)
downloadthis::download_file(path ="02_output/tables/prevalencia_departamento_edad.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [51]:
downloadthis::download_file(path ="02_output/tables/prevalencia_departamento_edad.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/prevalencia_departamento_edad_sexo.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [56]:
downloadthis::download_file(path ="02_output/tables/prevalencia_departamento_edad_sexo.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
In [57]:
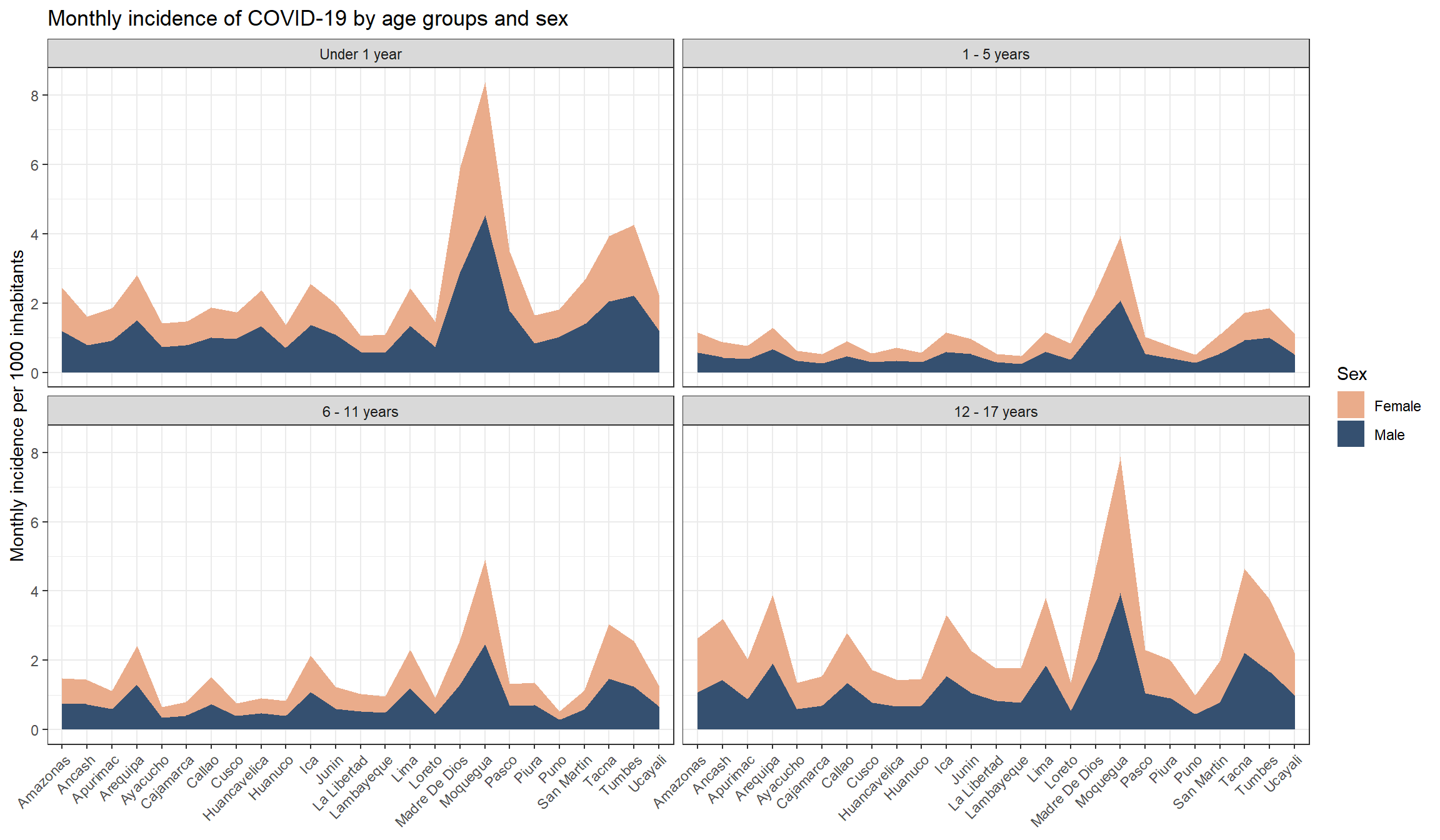
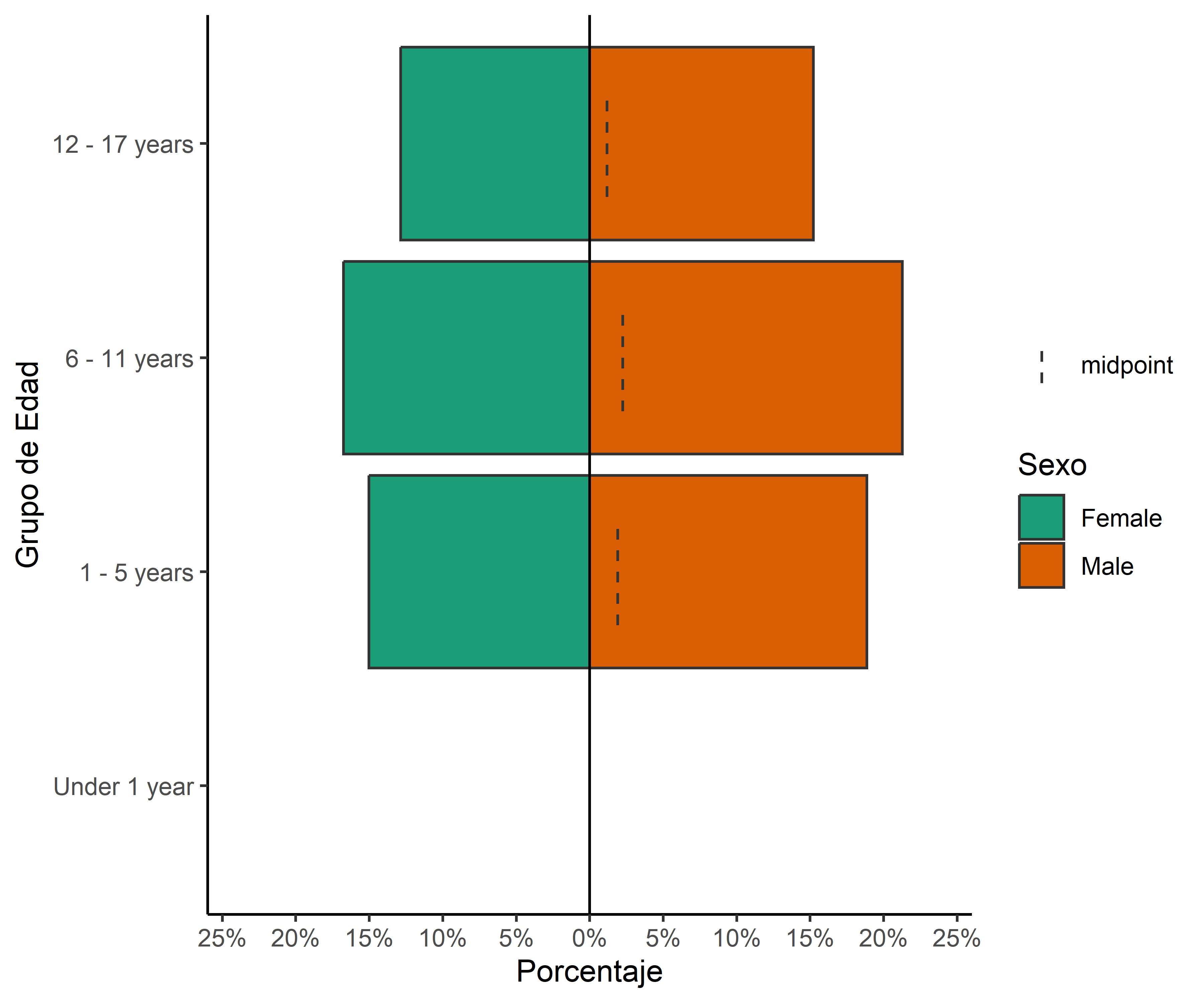
results_prevalencia$departamento_sexo_grupo_edad$index %>%mutate(departamento =str_to_title(departamento) ) %>%ggplot(aes(x = departamento,y = rate,fill = sexo,group = sexo ) ) +geom_area() +facet_wrap(vars(grupo_edad)) + innovar::scale_fill_innova("blue_fall") +labs(y ="Mean monthly COVID-19 incidence",x =NULL,title ="Monthly incidence of COVID-19 by age groups and sex",fill ="Sex" ) +theme_bw() +theme(axis.text.x =element_text(angle =45,hjust =1,vjust =1 ) )
Figura 8: Prevalencia COVID-19 de acuerdo al departamento, sexo y edad (07-03-2020 a 17-06-2023)
Departamento y olas
In [58]:
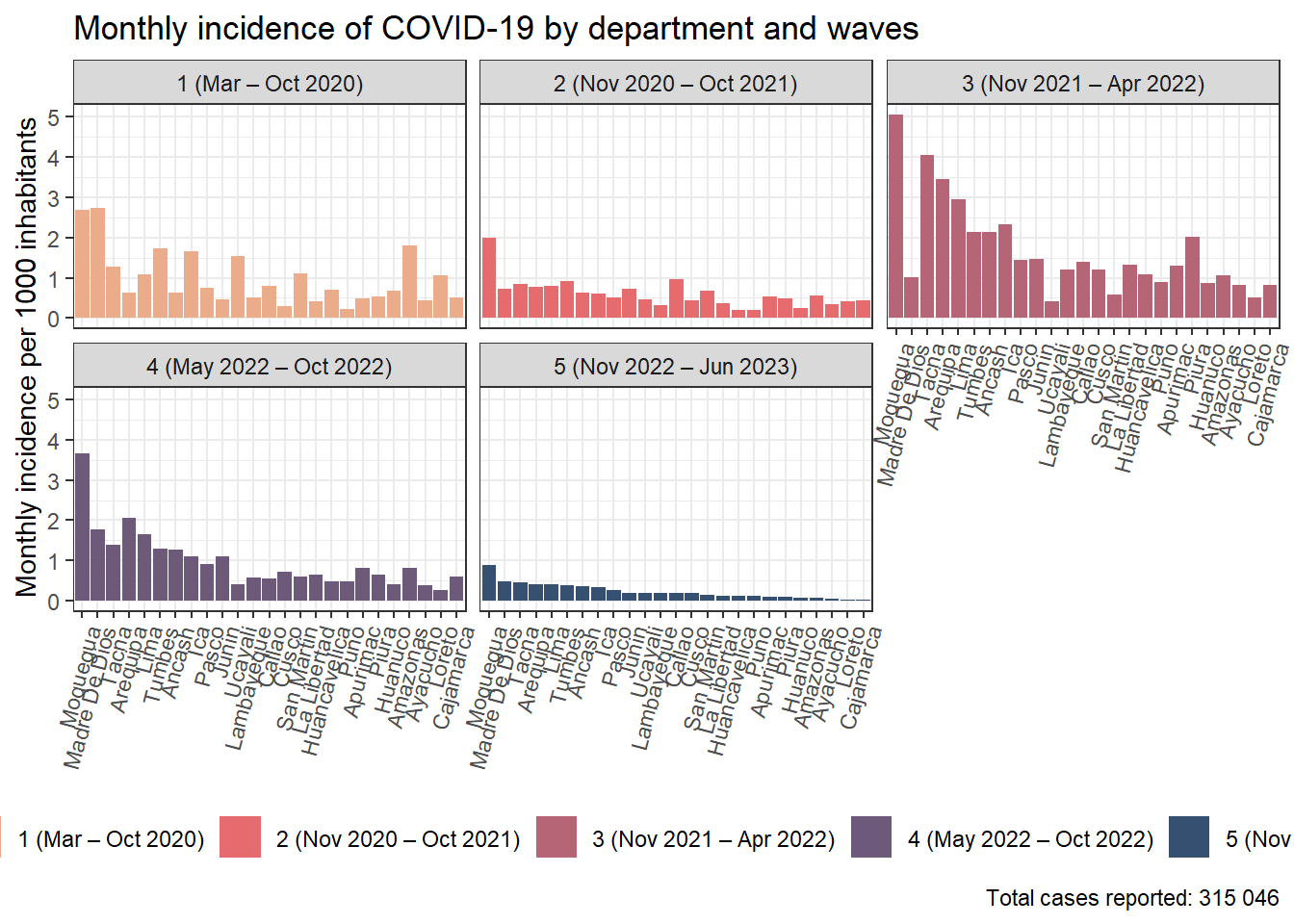
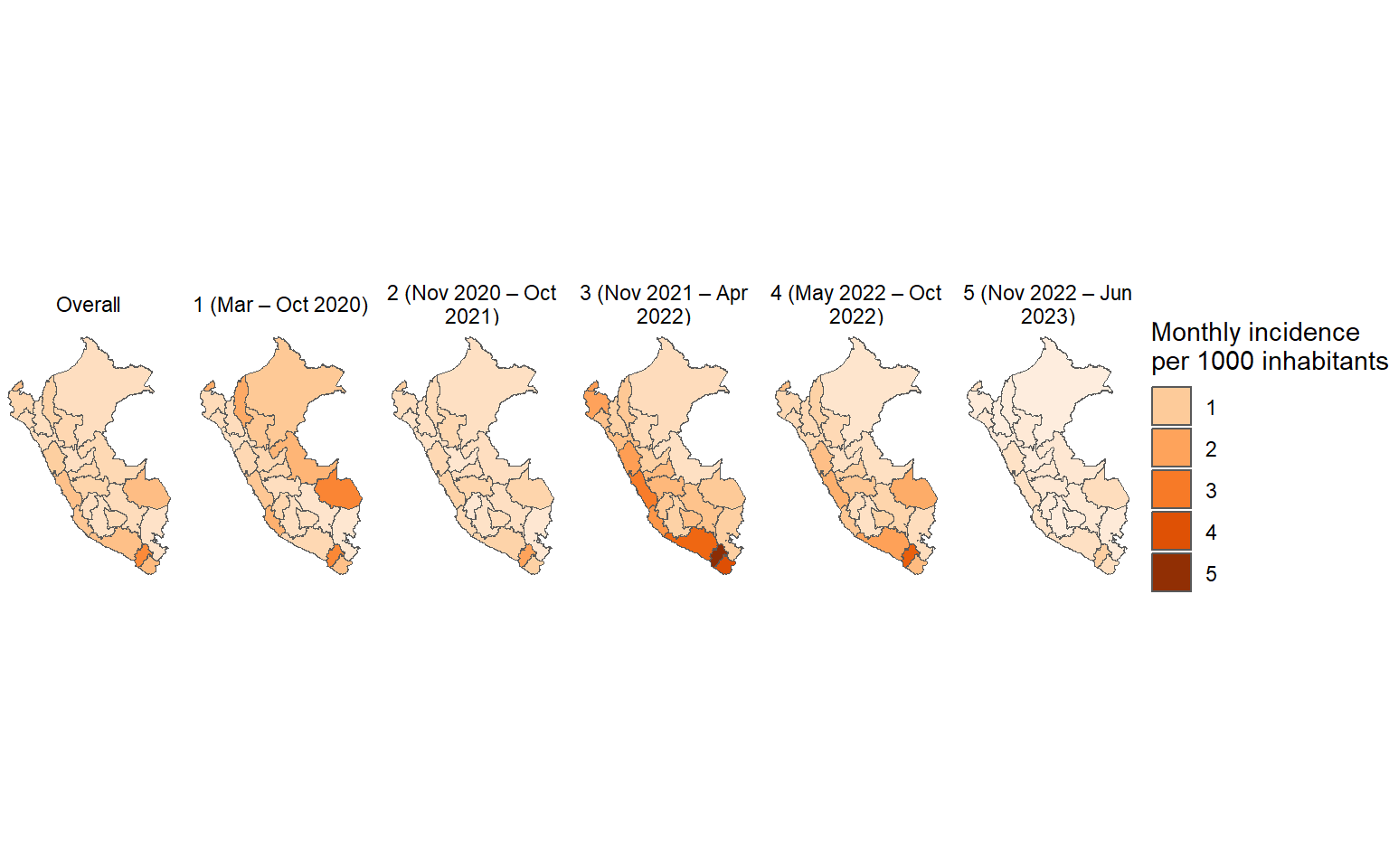
results_prevalencia$departamento_ola_covid$index %>%drop_na(ola_covid) %>%mutate(departamento =str_to_title(departamento),departamento =fct_reorder2(departamento, ola_covid, rate) ) %>%ggplot(aes(x = departamento, y = rate, fill = ola_covid)) +geom_bar(stat ="identity") +theme_bw() +labs(title ="Monthly incidence of COVID-19 by department and waves", x =NULL, y ="Mean monthly COVID-19 incidence",fill ="Sexo",caption =paste0("Total cases reported: ", scales::number(sum(pull(results_prevalencia$departamento_ola_covid$index_pre, count))))) + innovar::scale_fill_innova("blue_fall") +facet_wrap(vars(ola_covid)) +theme(axis.text.x =element_text(angle =75,hjust =1,vjust =1 ),legend.position ="bottom" )
Figura 9: Prevalencia COVID-19 de acuerdo al departamento y olas covid (07-03-2020 a 17-06-2023)
downloadthis::download_file(path ="02_output/tables/prevalencia_departamento_ola.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [65]:
downloadthis::download_file(path ="02_output/tables/prevalencia_departamento_ola.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
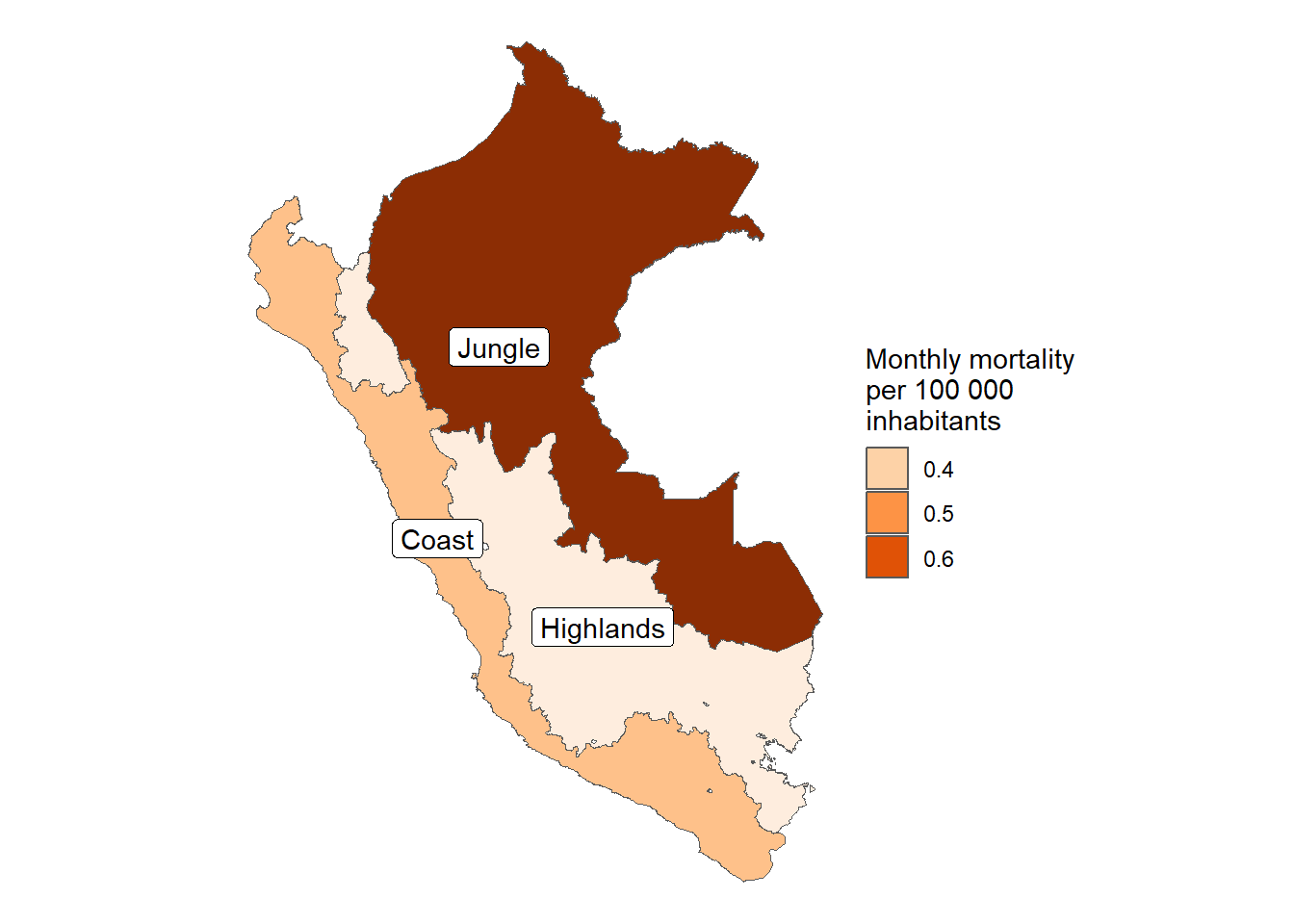
Regiones
In [66]:
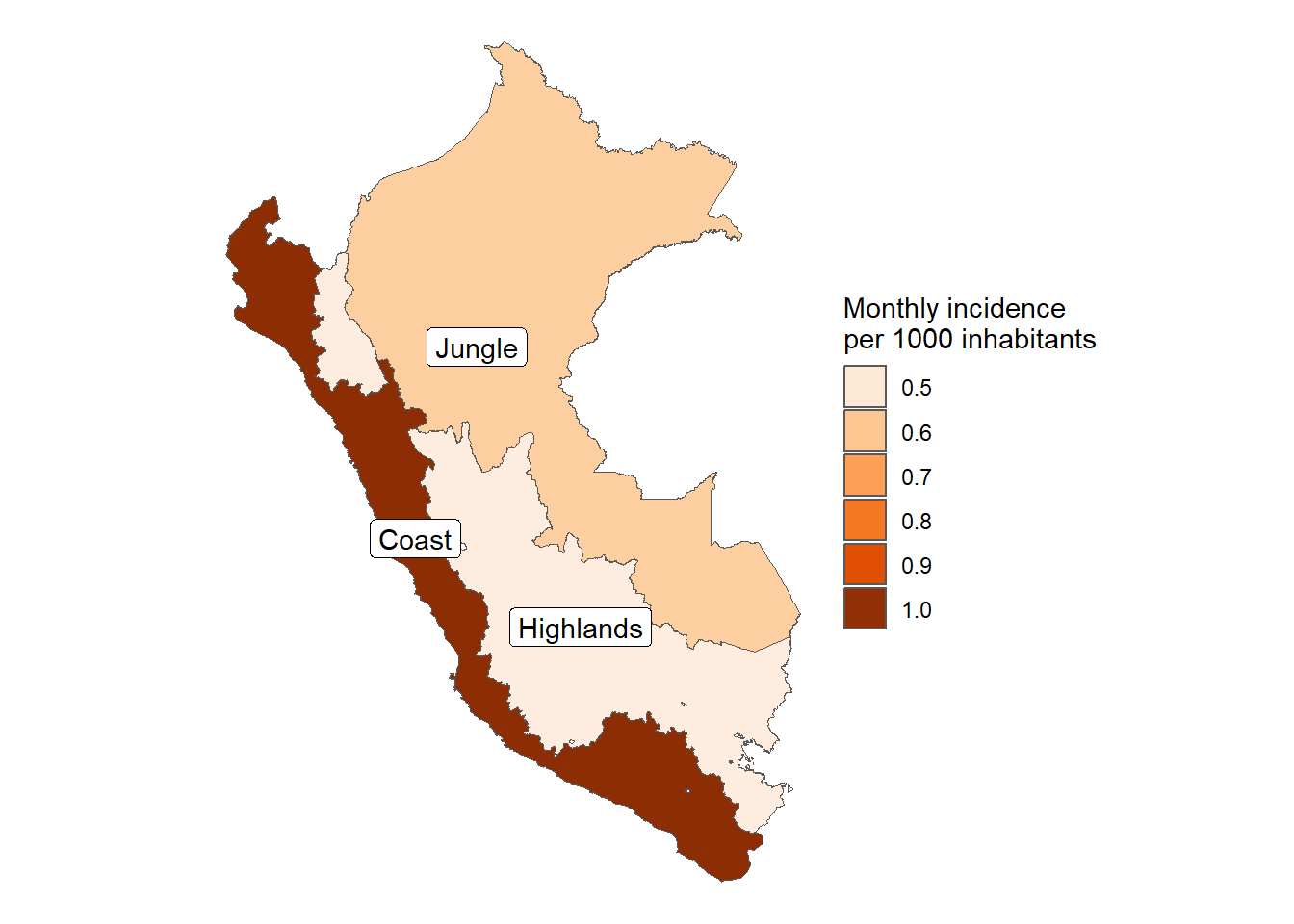
results_prevalencia$region$index %>%ggplot(aes(x = region, y = rate, fill = region)) +geom_bar(stat ="identity") +theme_bw() +labs(title ="Monthly incidence of COVID-19 by natural regions", x =NULL, y ="Mean monthly COVID-19 incidence",fill ="Sex",caption =paste0("Total cases reported: ", scales::number(sum(pull(results_prevalencia$region$index_pre, count))))) + innovar::scale_fill_innova("blue_fall") +theme(legend.position ="bottom" )
Figura 11: Prevalencia COVID-19 de acuerdo a la región (07-03-2020 a 17-06-2023)
downloadthis::download_file(path ="02_output/tables/prevalencia_region.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [73]:
downloadthis::download_file(path ="02_output/tables/prevalencia_region.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
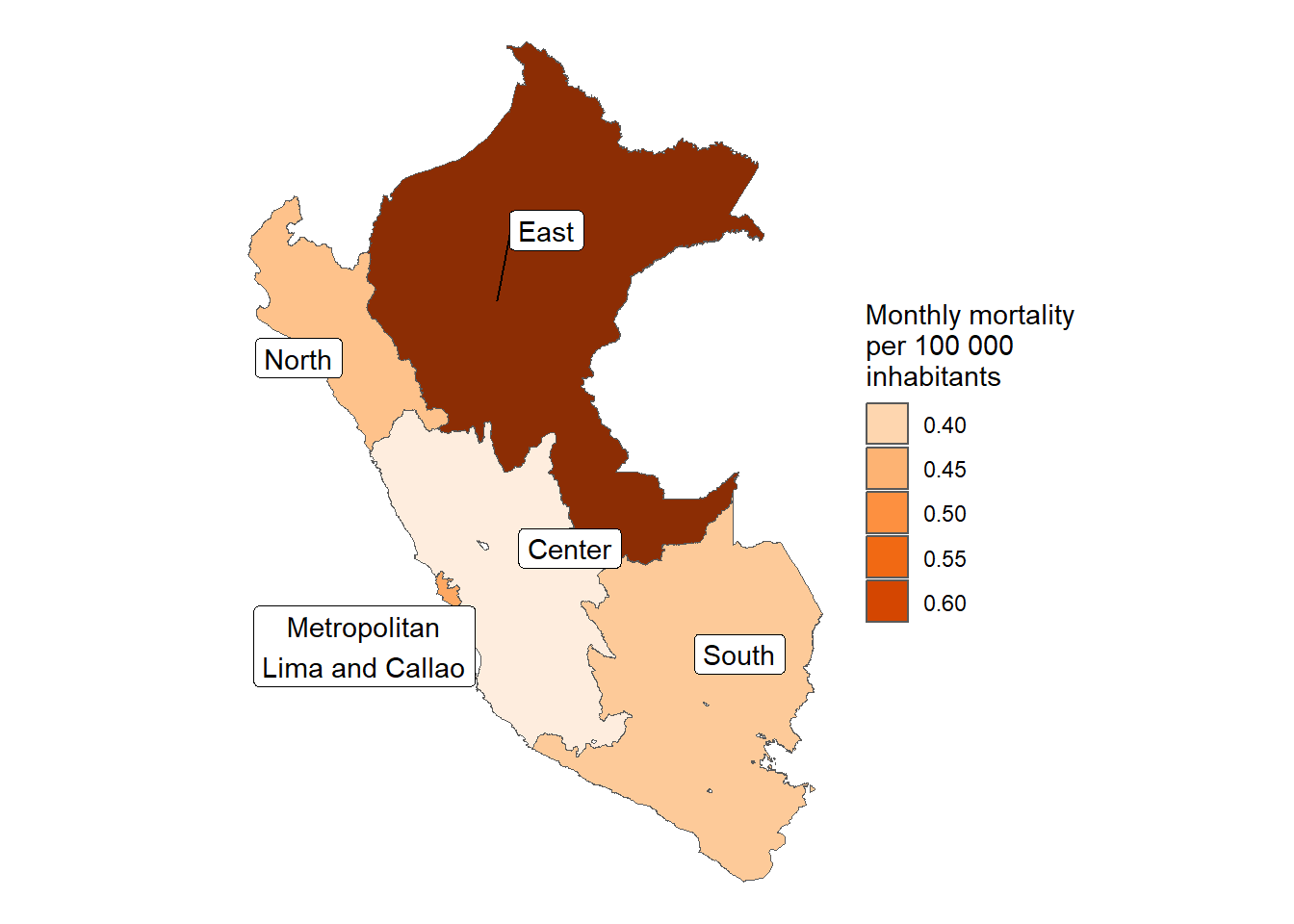
Macrorregión
In [74]:
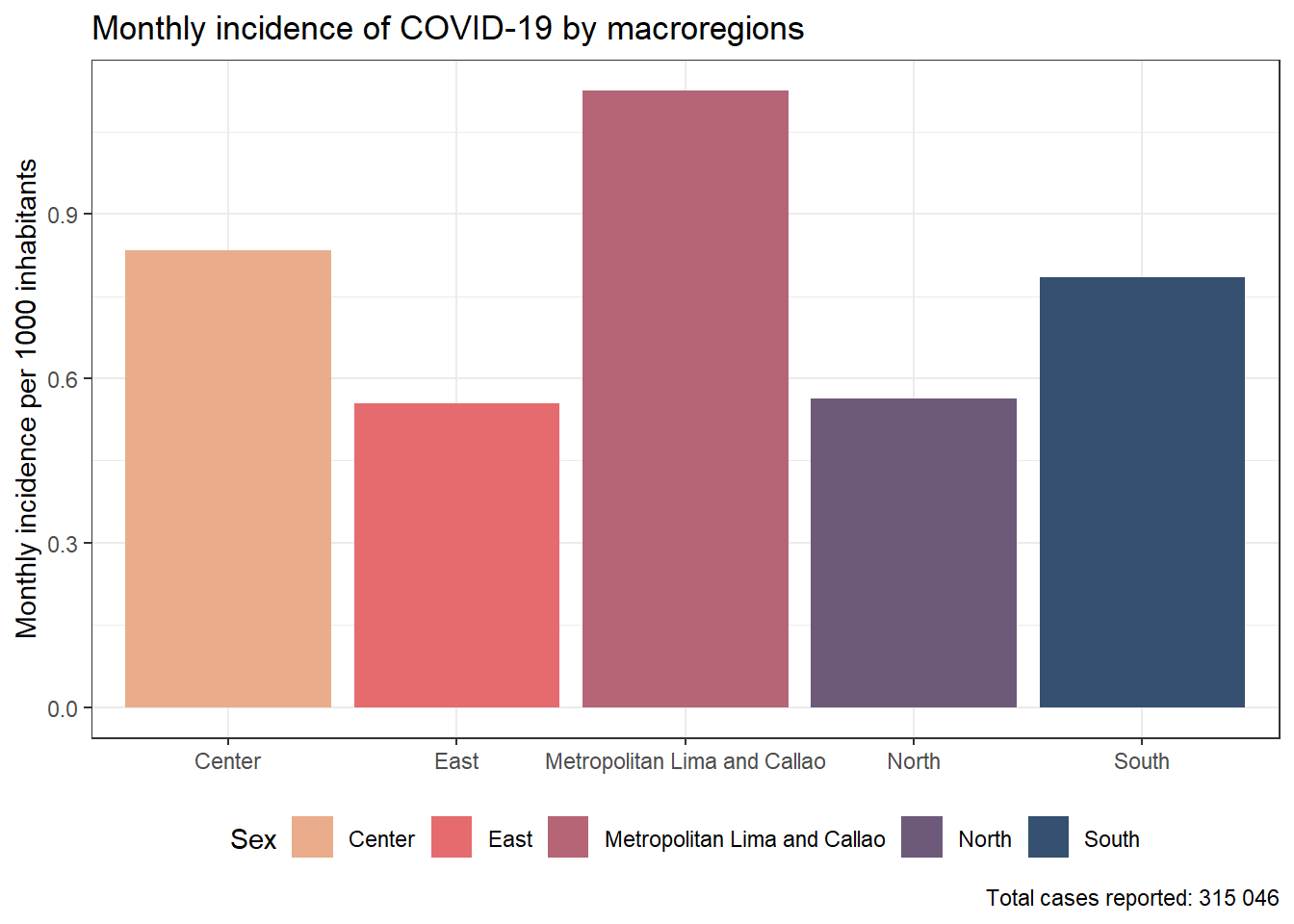
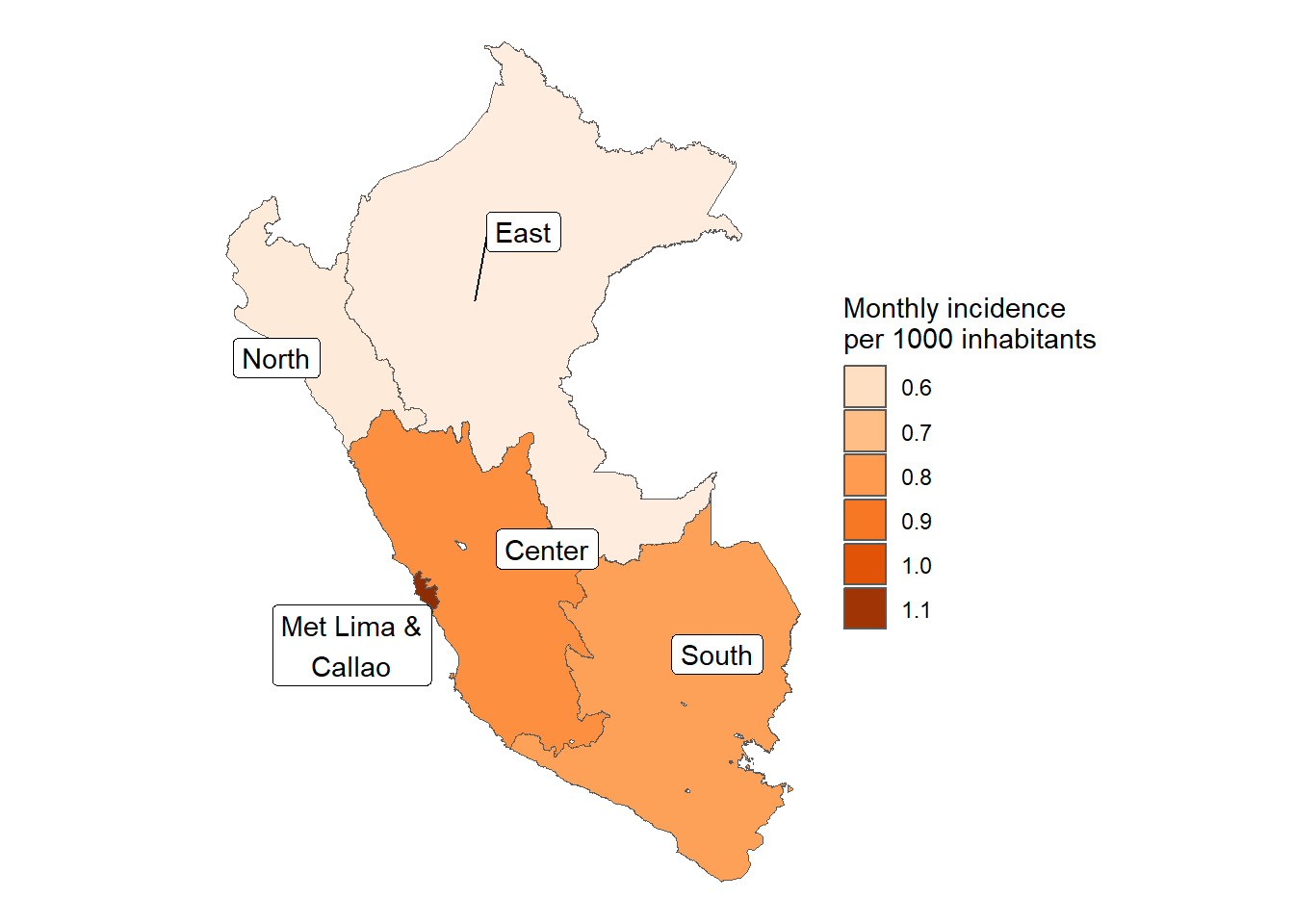
results_prevalencia$macrorregion$index %>%ggplot(aes(x = macrorregion, y = rate, fill = macrorregion)) +geom_bar(stat ="identity") +theme_bw() +labs(title ="Monthly incidence of COVID-19 by macroregions", x =NULL, y ="Mean monthly COVID-19 incidence",fill ="Sex",caption =paste0("Total cases reported: ", scales::number(sum(pull(results_prevalencia$macrorregion$index_pre, count))))) + innovar::scale_fill_innova("blue_fall") +theme(legend.position ="bottom" )
Figura 13: Prevalencia COVID-19 de acuerdo a la macrorregión (07-03-2020 a 17-06-2023)
downloadthis::download_file(path ="02_output/tables/prevalencia_macrorregion.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [81]:
downloadthis::download_file(path ="02_output/tables/prevalencia_macrorregion.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
Distrito y sexo
In [82]:
prev_distr_sex_1k_sf <- Peru %>%inner_join( results_prevalencia$distrito_sexo$index ) %>%ungroup()
downloadthis::download_file(path ="02_output/tables/prevalencia_distrito_sexo.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [88]:
downloadthis::download_file(path ="02_output/tables/prevalencia_distrito_sexo.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/prevalencia_distrito_edad.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [95]:
downloadthis::download_file(path ="02_output/tables/prevalencia_distrito_edad.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
Distrital y pobreza
In [96]:
library(biscale)
In [97]:
prev_distr_pobr_1k_sf <- Peru %>%inner_join( results_prevalencia$distrito_cuartil_pobreza$index ) %>%ungroup()
Joining with `by = join_by(ubigeo)`
prev_distr_pobr_biscale <-bi_class(prev_distr_pobr_1k_sf,x = rate,y = cuartil_pobreza,style ="quantile", dim =4)
In [98]:
custom_pal <-c("1-1"="#dae7f3", # Azul muy claro - Bajo en COVID, bajo en pobreza"2-1"="#b6cee1", # Azul medio claro - Bajo en COVID, moderado en pobreza"3-1"="#92b5cf", # Azul medio - Bajo en COVID, alto en pobreza"4-1"="#6e9cbd", # Azul oscuro - Bajo en COVID, muy alto en pobreza"1-2"="#d8f2bc", # Verde muy claro - Alto en COVID, bajo en pobreza"2-2"="#a9d985", # Verde medio claro - Alto en COVID, moderado en pobreza"3-2"="#7bc04e", # Verde medio - Alto en COVID, alto en pobreza"4-2"="#4ca717", # Verde oscuro - Alto en COVID, muy alto en pobreza"1-3"="#f8d4a0", # Naranja muy claro - Bajo en pobreza, bajo en COVID"2-3"="#f6b86c", # Naranja medio claro - Moderado en pobreza, bajo en COVID"3-3"="#f59b38", # Naranja medio - Alto en pobreza, bajo en COVID"4-3"="#f37e04", # Naranja oscuro - Muy alto en pobreza, bajo en COVID"1-4"="#f8bfcb", # Rosa muy claro - Muy alto en COVID, bajo en pobreza"2-4"="#f196a0", # Rosa medio claro - Muy alto en COVID, moderado en pobreza"3-4"="#ea6d75", # Rosa medio - Muy alto en COVID, alto en pobreza"4-4"="#e3444a"# Rosa oscuro - Muy alto en COVID, muy alto en pobreza)legend <-bi_legend(pal = custom_pal,dim =4,xlab ="Incidence",ylab ="Poverty Quartiles",size =5)ggmap <- prev_distr_pobr_biscale %>%ggplot() +geom_sf(aes(fill = bi_class), linewidth =0.01,show.legend =FALSE) +bi_scale_fill(pal = custom_pal, dim =4) +# bi_scale_color(pal = "GrPink", dim = 3) +bi_theme()library(cowplot)
Adjuntando el paquete: 'cowplot'
The following object is masked from 'package:lubridate':
stamp
downloadthis::download_file(path ="02_output/tables/prevalencia_distritos_pobreza_descriptivos_by_dep.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [103]:
downloadthis::download_file(path ="02_output/tables/prevalencia_distritos_pobreza_descriptivos_by_dep.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
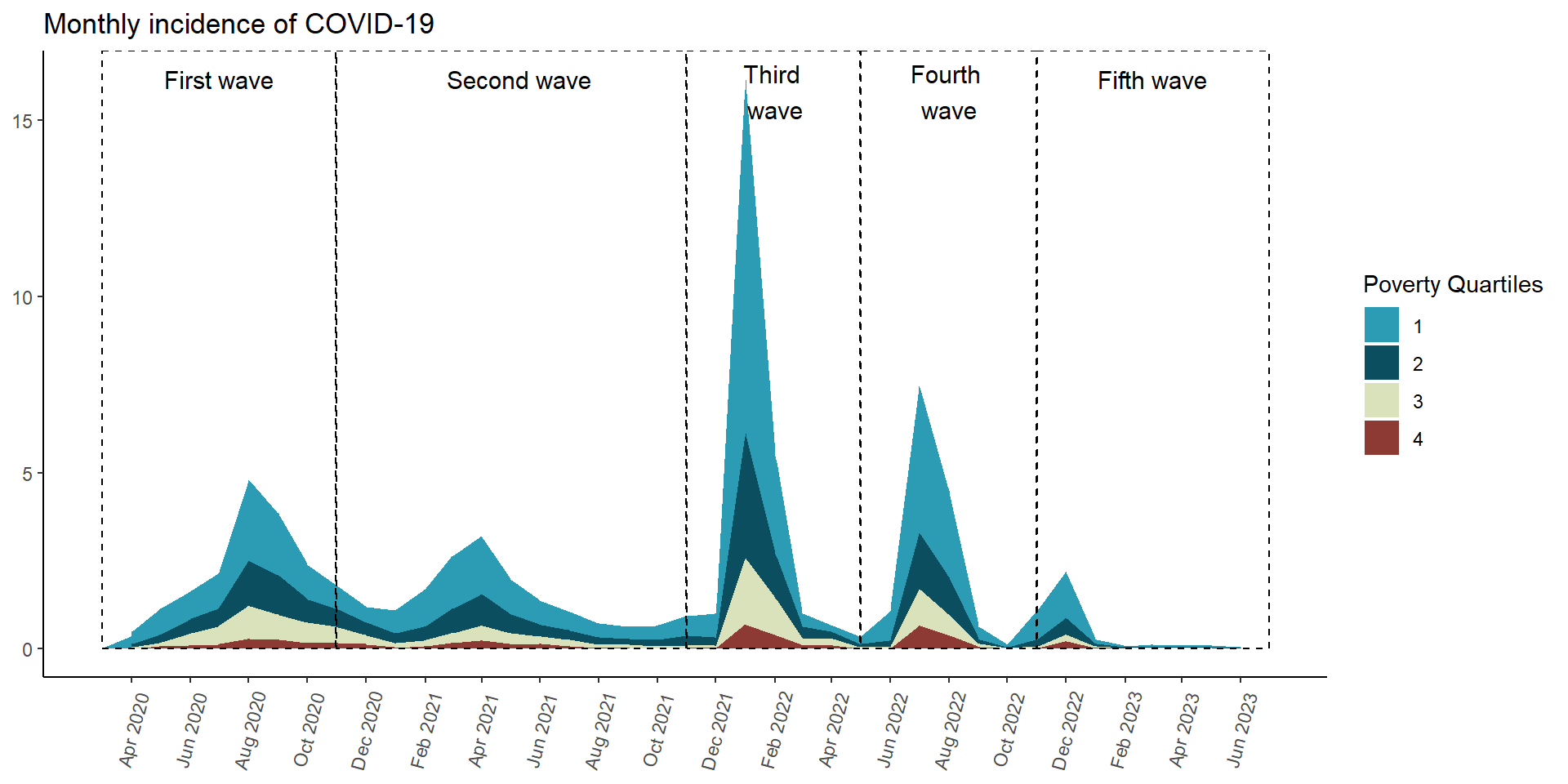
In [104]:
prev_pobr_area_plot <- results_per_month_prevalencia$cuartil_pobreza$index %>%drop_na() %>%mutate(time =make_date(anio, mes, "1") ) %>%ggplot(aes(x = time,y = rate,fill = cuartil_pobreza) ) +geom_area(position ='stack') +# innovar::scale_fill_innova("jama") +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#DAE2BC", "#8C3A33") ) +scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +labs(y =NULL,x =NULL,title ="Monthly incidence of COVID-19",fill ="Poverty Quartiles" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =as.Date("2023-07-01"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"),y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() ) prev_pobr_area_plot
Figura 18: Prevalencia COVID-19 de acuerdo al cuartil de pobreza(07-03-2020 a 17-06-2023)
Distrito Lima
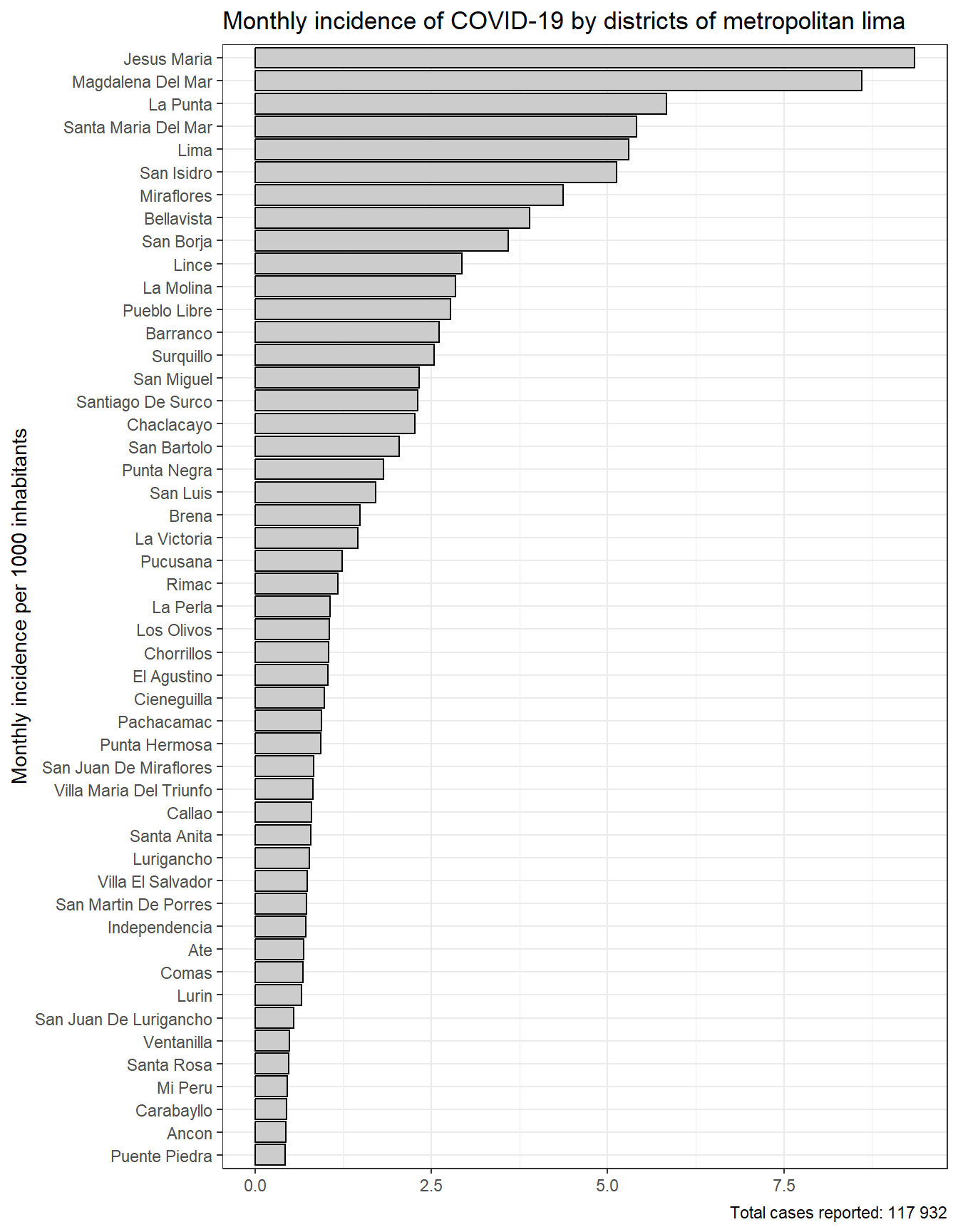
In [105]:
total_cases_distr_lim_callao <- results_prevalencia$distrito$index_pre %>%filter(provincia %in%c("LIMA", "CALLAO")) %>%pull(count) %>%sum()results_prevalencia$distrito$index %>%filter(provincia %in%c("LIMA", "CALLAO")) %>%mutate(distrito =str_to_title(distrito), distrito =fct_reorder(distrito, rate) ) %>%ggplot(aes(y = distrito, x = rate)) +geom_bar(stat ="identity",color ="black",fill ="grey80") +theme_bw() +labs(title ="Monthly incidence of COVID-19 by districts of metropolitan lima", x =NULL, y ="Mean monthly COVID-19 incidence",caption =paste0("Total cases reported: ", scales::number(total_cases_distr_lim_callao))) + innovar::scale_fill_innova("blue_fall") +theme(legend.position ="bottom" )
Figura 19: Prevalencia COVID-19 de acuerdo a los distritos de lima metropolitana (07-03-2020 a 17-06-2023)
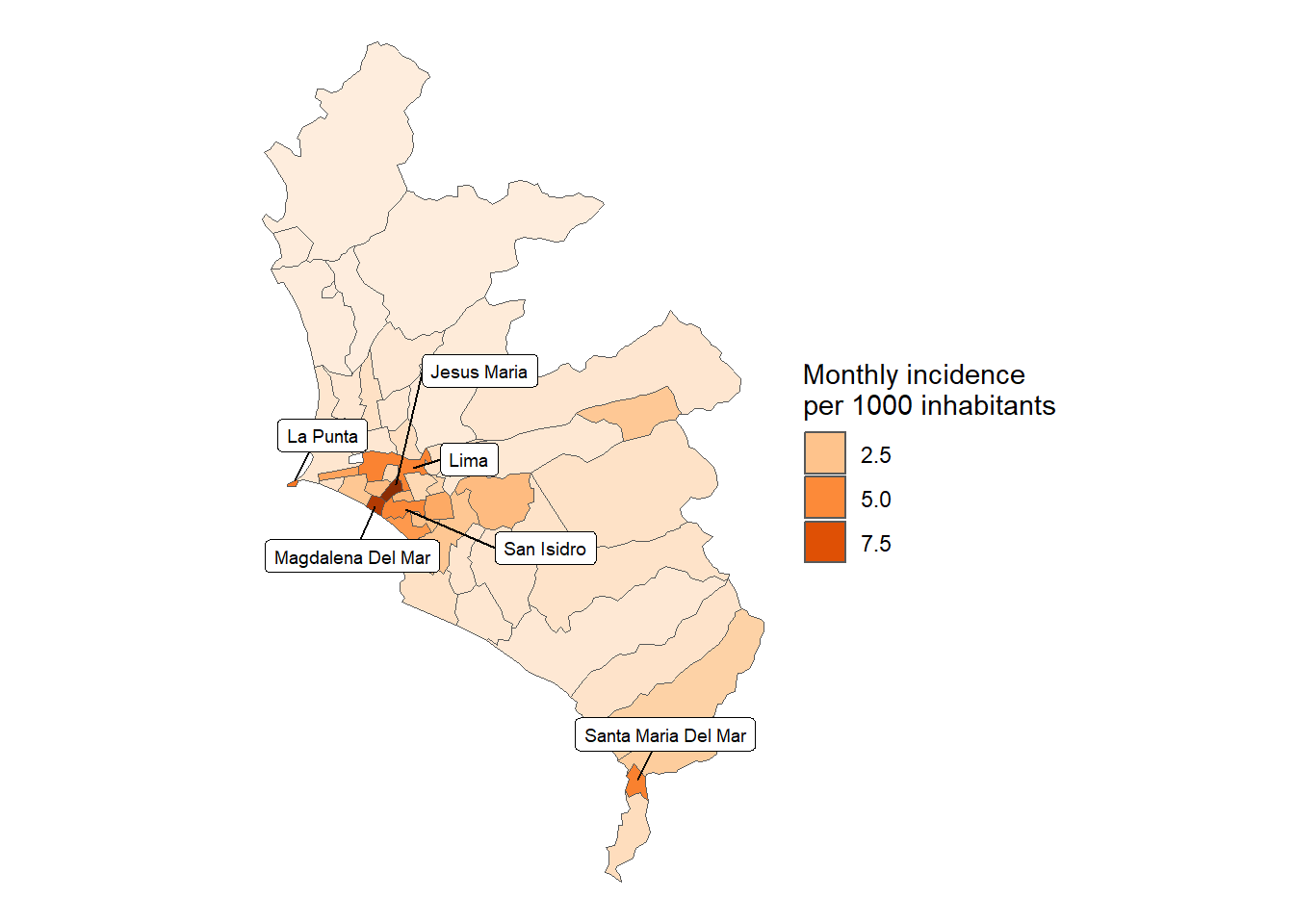
In [106]:
prev_lima_distr_1k_sf <- Peru %>%inner_join( results_prevalencia$distrito$index %>%filter(provincia %in%c("LIMA", "CALLAO")) )
downloadthis::download_file(path ="02_output/tables/prevalencia_lima_distrito.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [112]:
downloadthis::download_file(path ="02_output/tables/prevalencia_lima_distrito.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/fallecidos_descriptivos.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [121]:
downloadthis::download_file(path ="02_output/tables/fallecidos_descriptivos.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
In [122]:
mortality_comparisons <-compare_levels_per_month(results_per_month = results_per_month_mortalidad,levels = comparing_levels)# Extraer las tablas `cld` como tibbles, renombrando y añadiendo una columna "level"mortality_comparisons_cld_pre <-lapply(names(mortality_comparisons), function(level) { cld <- mortality_comparisons[[level]]$cldif (!is.null(cld)) { cld <- cld |>as_tibble() |>rename(group =1) |># Renombra la primera columna a 'group'mutate(level = level) |># Añade una columna 'level' con el nombre de la listarelocate(level) } cld}) |>bind_rows()mortality_comparisons_cld_pre <- mortality_comparisons_cld_pre |>mutate(across(where(is.numeric),~ formattable::digits(.x, 3) ) )
downloadthis::download_file(path ="02_output/tables/mortalidad_comparacion_multiple.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [127]:
downloadthis::download_file(path ="02_output/tables/mortalidad_comparacion_multiple.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
In [128]:
lethality_comparisons <-compare_levels_per_month(results_per_month = results_per_month_letalidad,levels = comparing_levels)# Extraer las tablas `cld` como tibbles, renombrando y añadiendo una columna "level"lethality_comparisons_cld_pre <-lapply(names(lethality_comparisons), function(level) { cld <- lethality_comparisons[[level]]$cldif (!is.null(cld)) { cld <- cld |>as_tibble() |>rename(group =1) |># Renombra la primera columna a 'group'mutate(level = level) |># Añade una columna 'level' con el nombre de la listarelocate(level) } cld}) |>bind_rows()lethality_comparisons_cld_pre <- lethality_comparisons_cld_pre |>mutate(across(where(is.numeric),~ formattable::digits(.x, 3) ) )
downloadthis::download_file(path ="02_output/tables/letalidad_comparacion_multiple.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [133]:
downloadthis::download_file(path ="02_output/tables/letalidad_comparacion_multiple.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/fallecidos_olas_descriptivos.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [138]:
downloadthis::download_file(path ="02_output/tables/fallecidos_olas_descriptivos.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
Gráfico de muertes (serie de tiempo) - Menores de 18 años
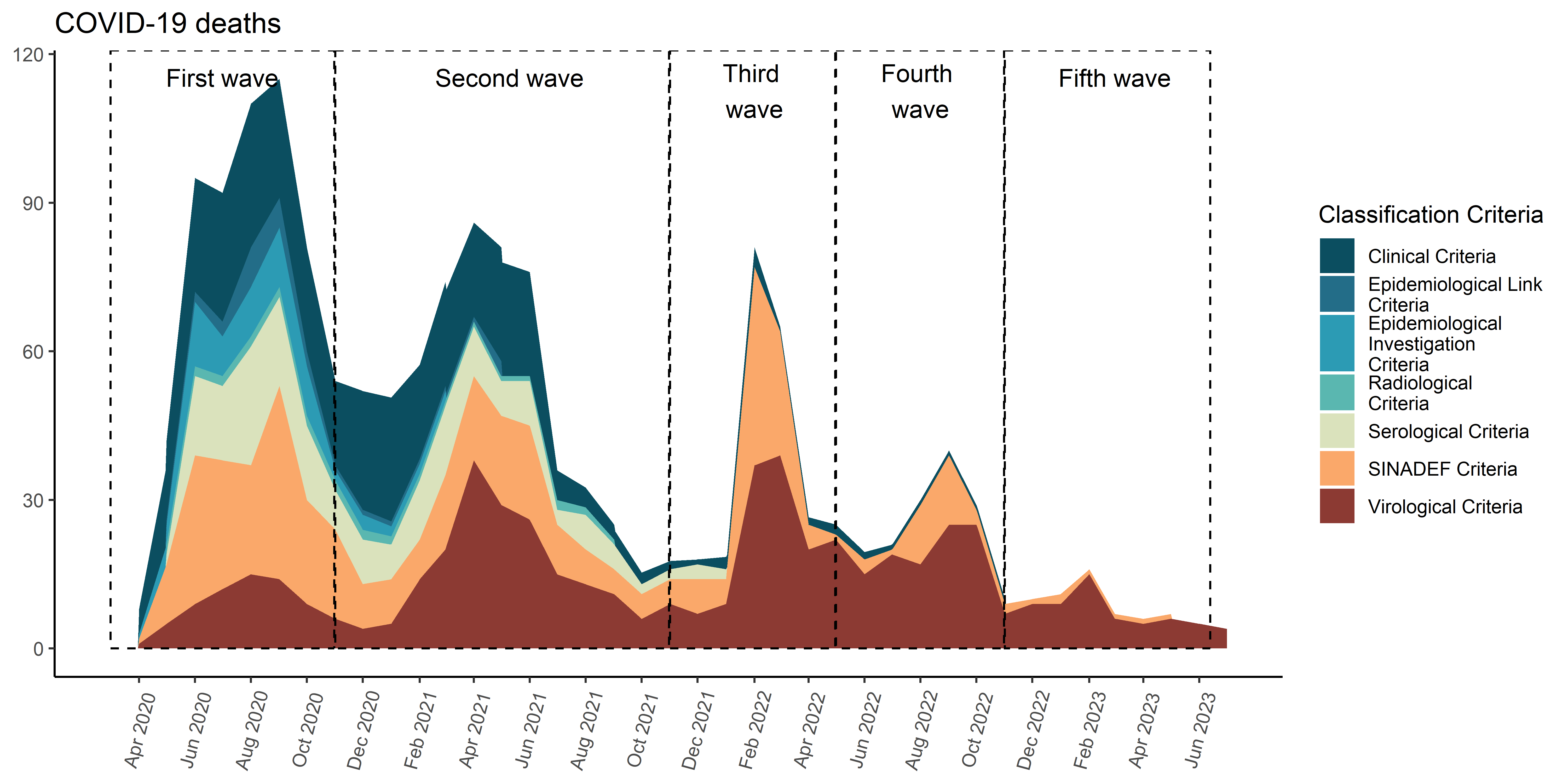
In [139]:
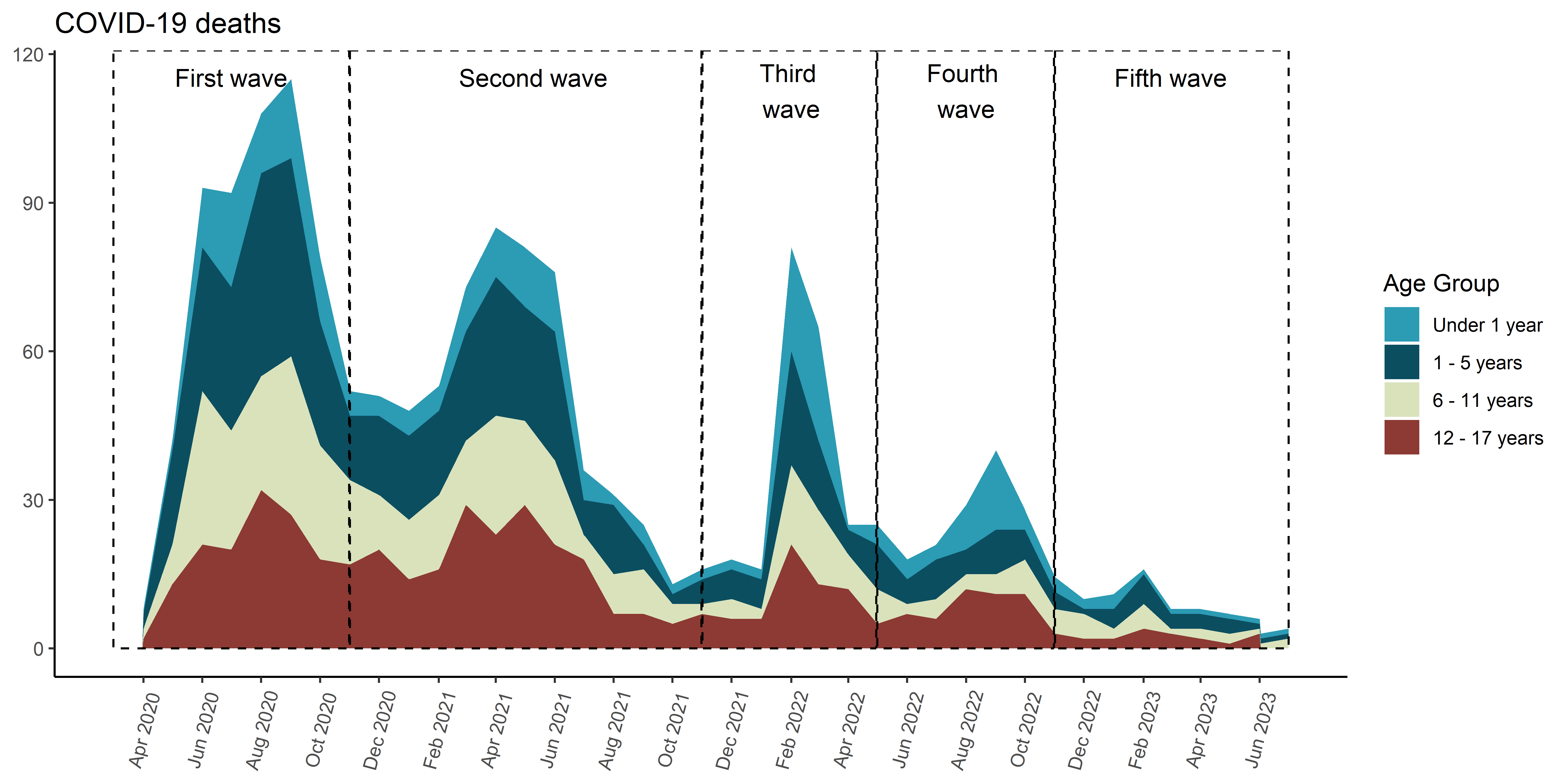
range_fallecidos_und_18 <- fallecidos_total %>%summarise(min =min(fecha_fallecimiento),max =max(fecha_fallecimiento) ) %>%collect()deaths_cases_area <- fallecidos_total %>%count(clasificacion_def, fecha_round) %>%mutate(clasificacion_def =case_match( clasificacion_def,"Criterio serológico"~"Serological Criteria","Criterio radiológico"~"Radiological Criteria","Criterio SINADEF"~"SINADEF Criteria","Criterio virológico"~"Virological Criteria","Criterio nexo epidemiológico"~"Epidemiological Link Criteria","Criterio clínico"~"Clinical Criteria","Criterio investigación Epidemiológica"~"Epidemiological Investigation Criteria",.default =NA_character_ ) ) %>%collect() %>%mutate(clasificacion_def =str_wrap(clasificacion_def,20) ) |>ggplot(aes(x = fecha_round,y = n,fill = clasificacion_def ) ) +geom_area(position ='stack') + innovar::scale_fill_innova("jama") +# scale_x_date(# limits = c(ymd("2020-03-01"), ymd("2023-10-31")),# breaks = scales::date_breaks("2 month"), # Cambiar a "6 months" para menos frecuencia# labels = scales::date_format("%b %Y") # Formato de fecha, %b es la abreviatura de mes, %Y es el año# ) + scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +labs(y =NULL,x =NULL,title ="COVID-19 deaths",fill ="Classification Criteria" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax = range_fallecidos_und_18$max, ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() ) deaths_cases_area
Gráfico de muertes (serie de tiempo) - Grupo Etáreo
In [140]:
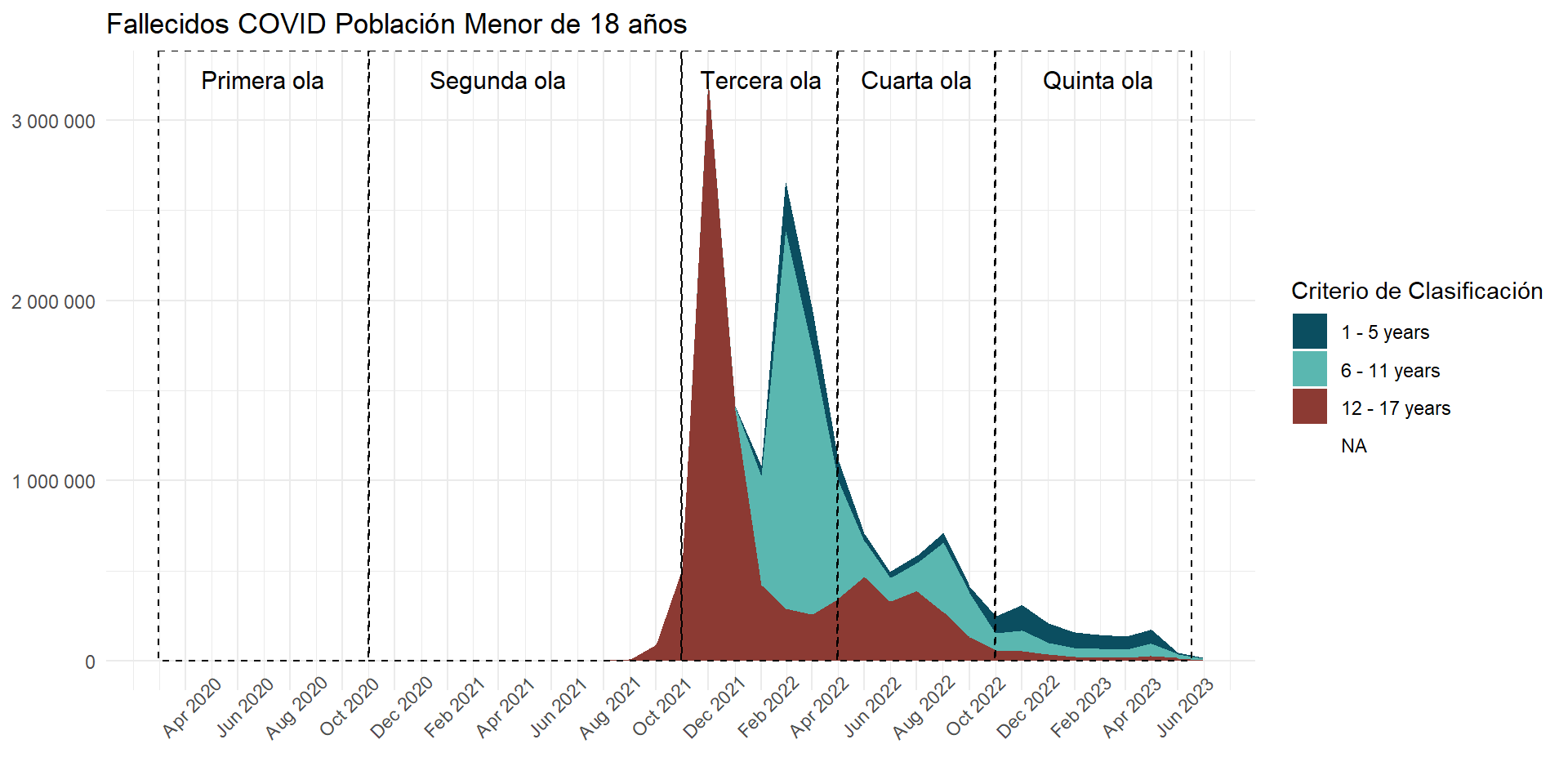
deaths_cases_by_age_area <- fallecidos_total %>%count(grupo_edad, fecha_round) %>%collect() %>%ggplot(aes(x = fecha_round,y = n,fill = grupo_edad ) ) +geom_area(position ='stack') +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#DAE2BC", "#8C3A33") ) +# scale_x_date(# limits = c(ymd("2020-03-01"), ymd("2023-10-31")),# breaks = scales::date_breaks("2 month"), # Cambiar a "6 months" para menos frecuencia# labels = scales::date_format("%b %Y") # Formato de fecha, %b es la abreviatura de mes, %Y es el año# ) + scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +labs(y =NULL,x =NULL,title ="COVID-19 deaths",fill ="Age Group" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =as.Date("2023-07-01"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"),y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() ) deaths_cases_by_age_area
Gráfico Mortalidad (serie de tiempo)
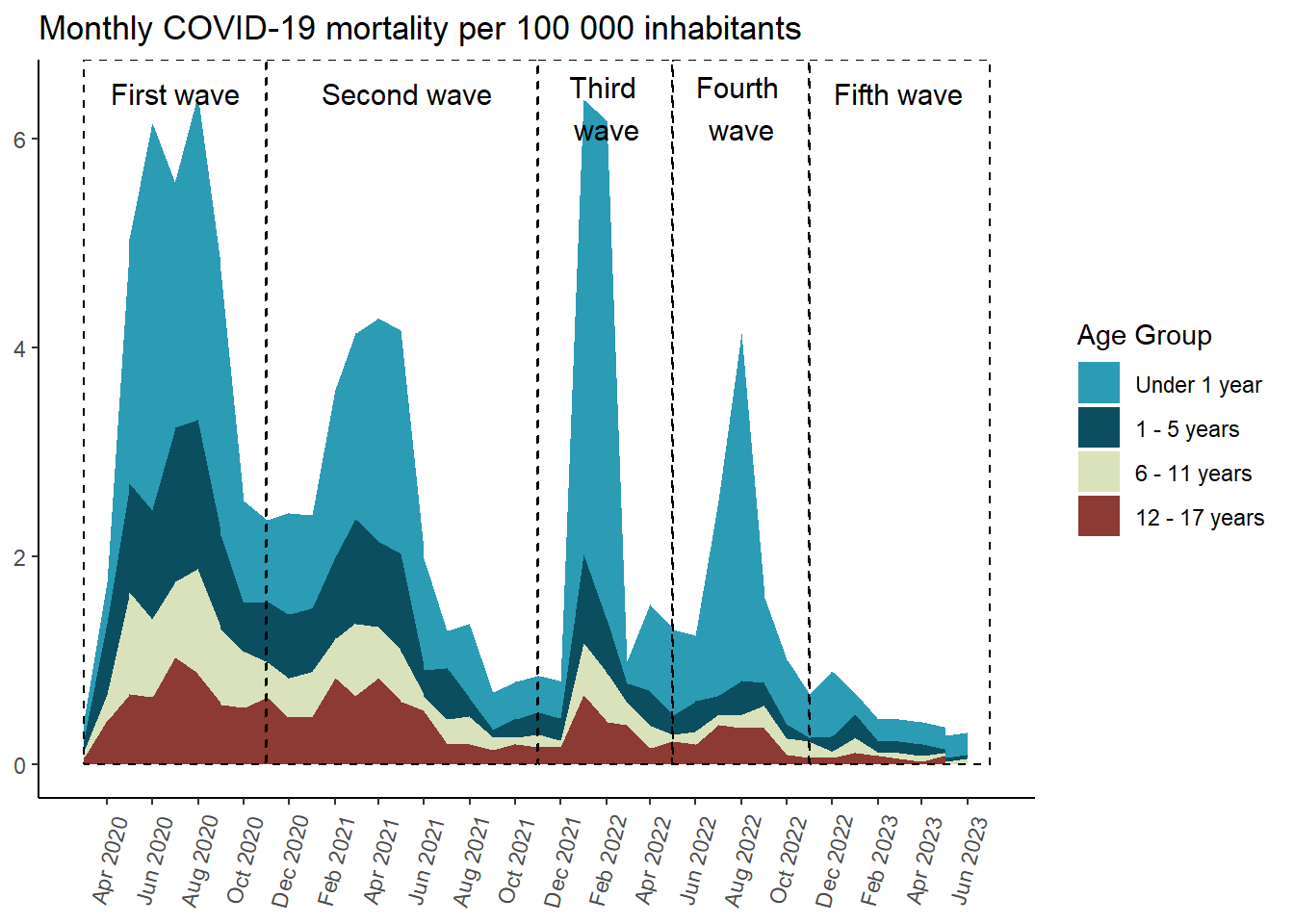
In [141]:
mortality_cases_by_age_area <- results_per_month_mortalidad$grupo_edad$index %>%mutate(time =make_date(anio, mes, "1") ) %>%ggplot(aes(x = time,y = rate,fill = grupo_edad ) ) +geom_area(position ='stack') +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#DAE2BC", "#8C3A33") ) +scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +labs(y =NULL,x =NULL,title ="Monthly COVID-19 mortality per 100 000 inhabitants",fill ="Age Group" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =as.Date("2023-07-01"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"),y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() ) mortality_cases_by_age_area
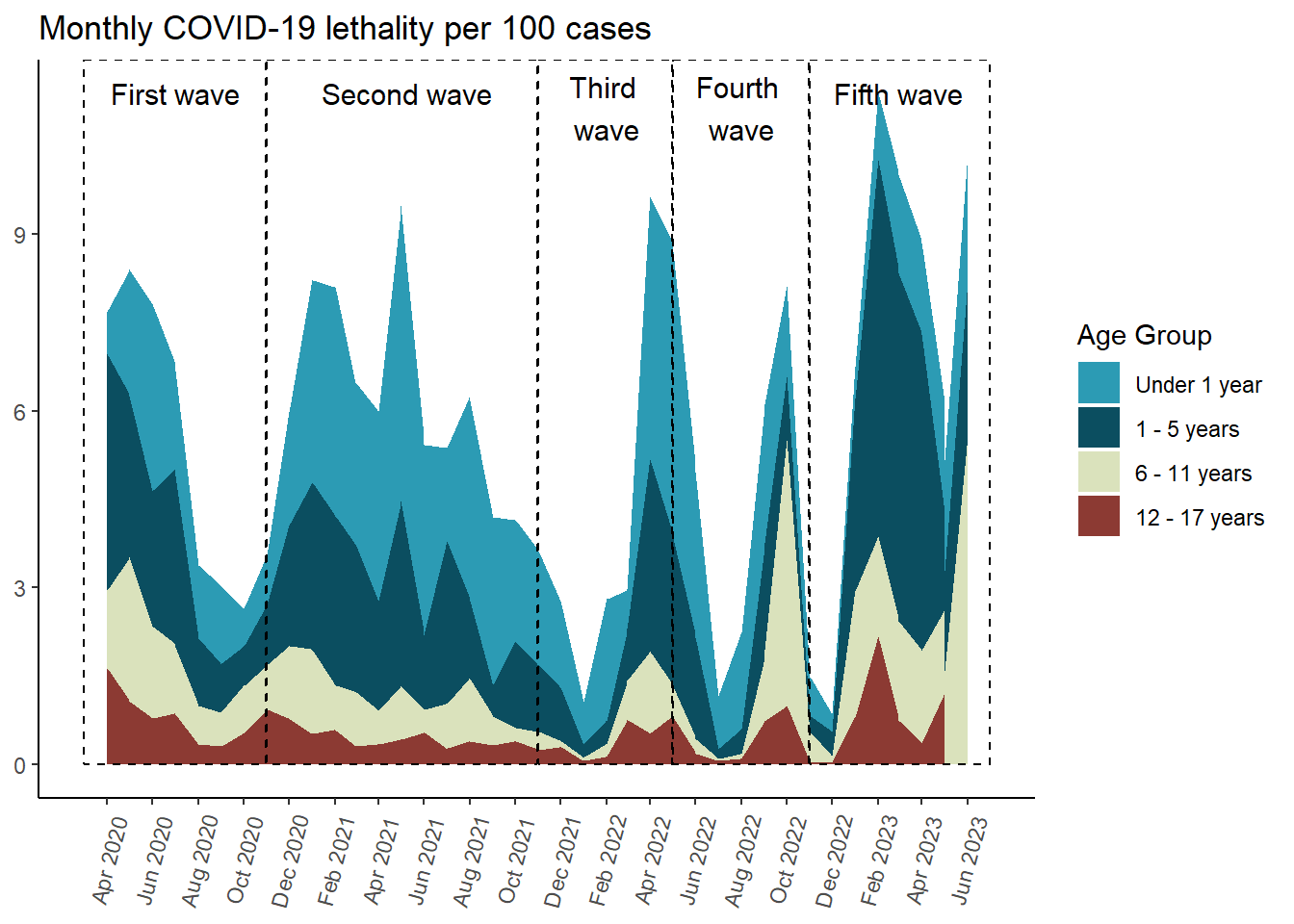
Gráfico Letalidad (serie de tiempo)
No se está mostrando en la gráfica la información de marzo de 2020, debido a la enorme diferencia entre su valor de letalidad con respecto al resto de letalidades.
lethality_cases_by_age_area <- results_per_month_letalidad$grupo_edad$index %>%mutate(time =make_date(anio, mes, "1") ) %>%filter( time >ymd("2020-03-01") ) |>ggplot(aes(x = time,y = rate,fill = grupo_edad ) ) +geom_area(position ='stack') +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#DAE2BC", "#8C3A33") ) +scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +labs(y =NULL,x =NULL,title ="Monthly COVID-19 lethality per 100 cases",fill ="Age Group" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =as.Date("2023-07-01"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"),y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() ) lethality_cases_by_age_area
downloadthis::download_file(path ="02_output/tables/mortalidad_departamento.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [154]:
downloadthis::download_file(path ="02_output/tables/mortalidad_departamento.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/mortalidad_departamento_sexo.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [161]:
downloadthis::download_file(path ="02_output/tables/mortalidad_departamento_sexo.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/mortalidad_departamento_edad.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [168]:
downloadthis::download_file(path ="02_output/tables/mortalidad_departamento_edad.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/mortalidad_departamento_ola.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [175]:
downloadthis::download_file(path ="02_output/tables/mortalidad_departamento_ola.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/mortalidad_region.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [182]:
downloadthis::download_file(path ="02_output/tables/mortalidad_region.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/mortalidad_departamento_edad.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [189]:
downloadthis::download_file(path ="02_output/tables/mortalidad_departamento_edad.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
Warning in st_point_on_surface.sfc(data$geometry): st_point_on_surface may not
give correct results for longitude/latitude data
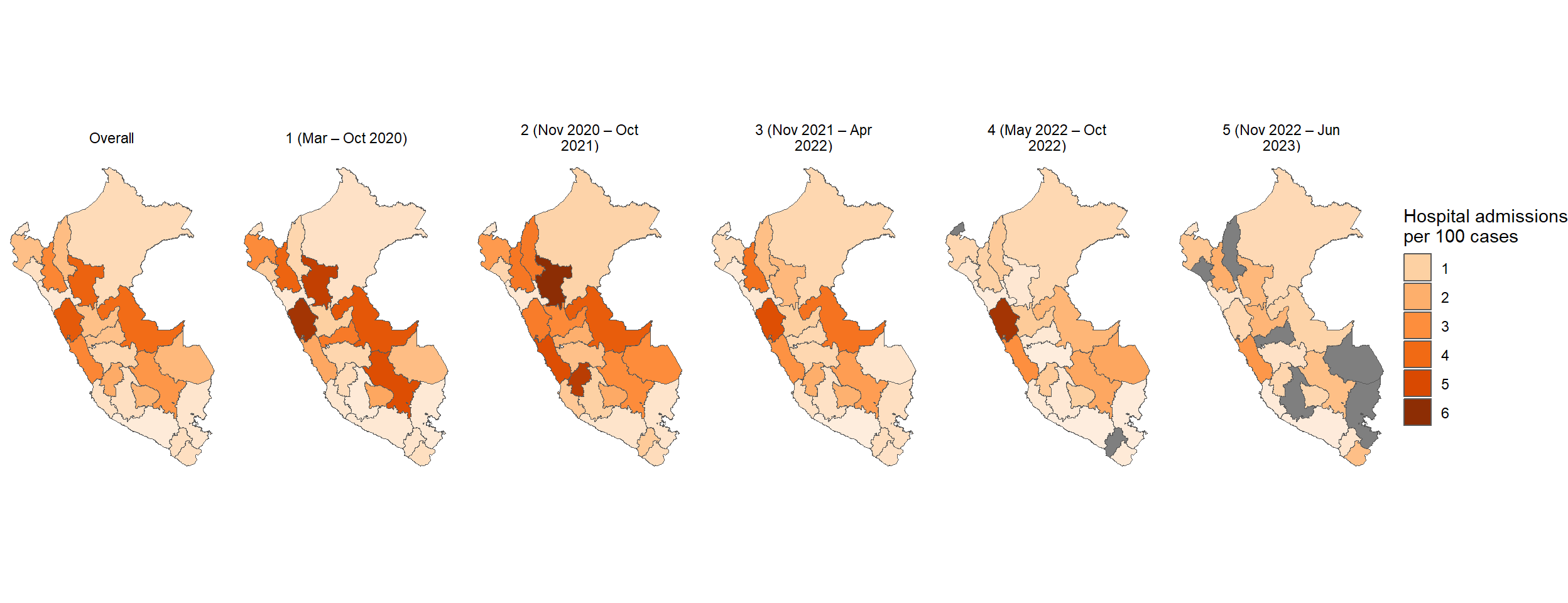
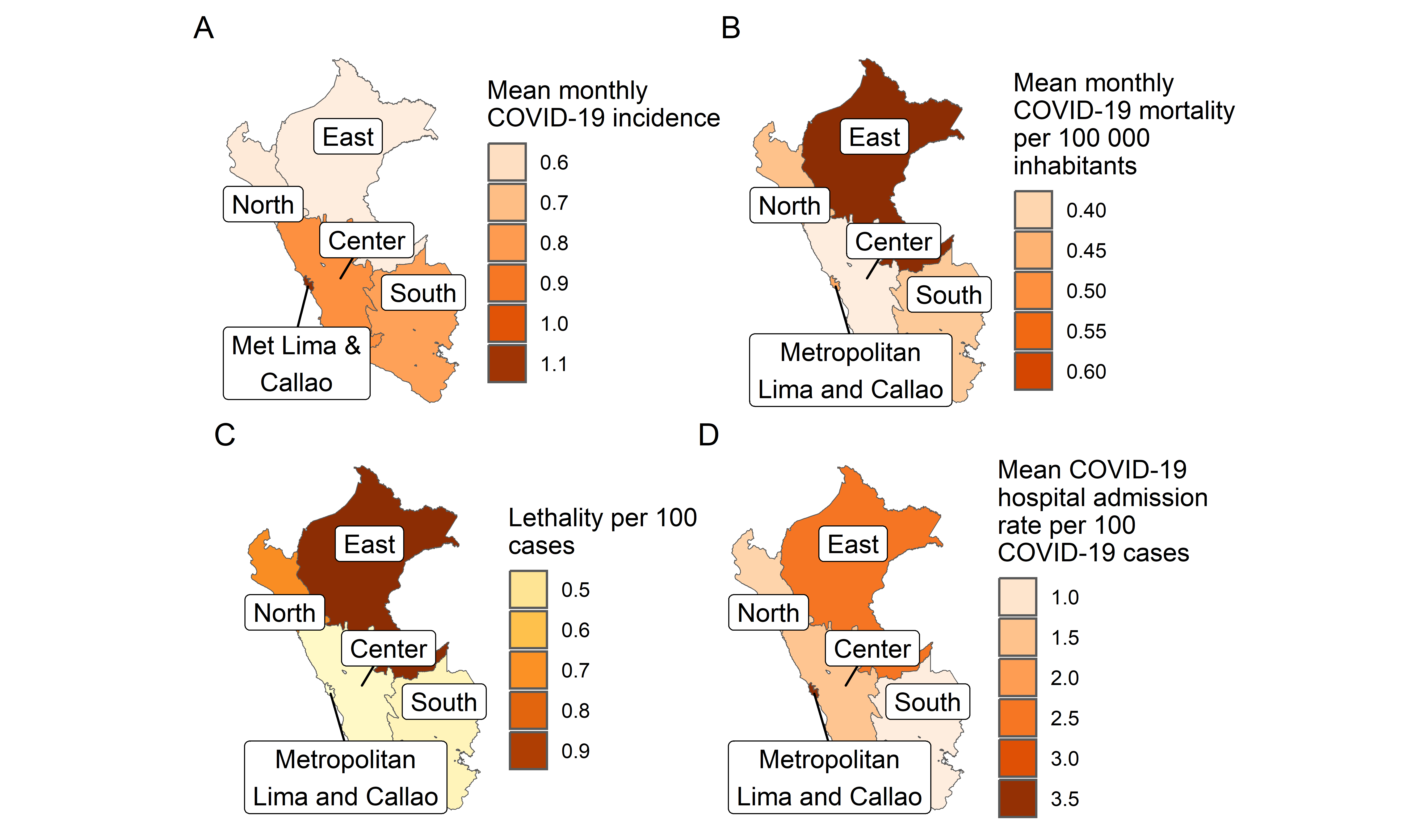
Figura 26: Letalidad COVID-19 por 100K habitantes de acuerdo a la macrorregión (14-03-2020 a 13-06-2023)
Distrital y pobreza
In [192]:
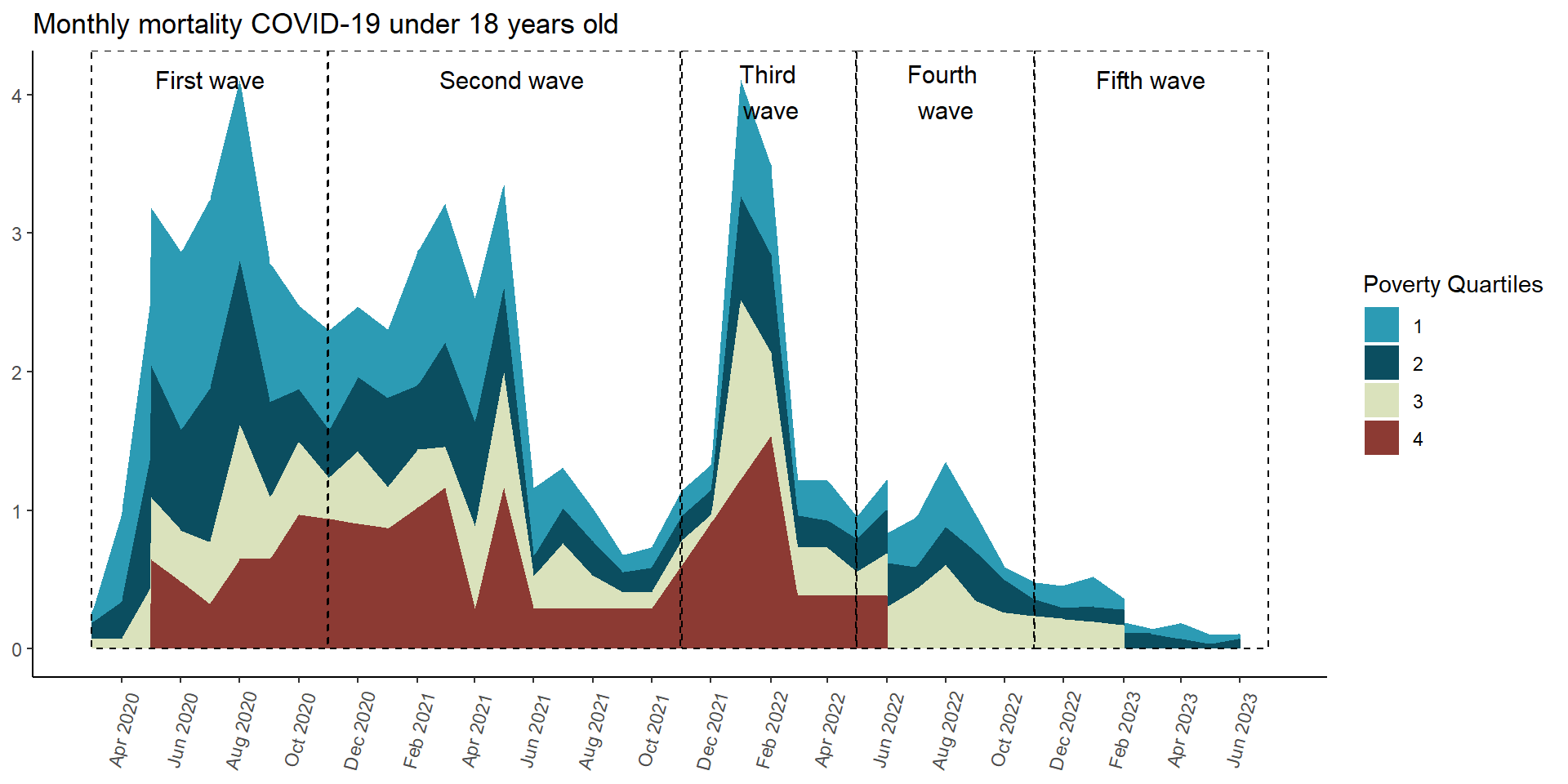
mort_pobr_area_plot <- results_per_month_mortalidad$cuartil_pobreza$index %>%drop_na() %>%mutate(time =make_date(anio, mes, "1") ) %>%ggplot(aes(x = time,y = rate,fill = cuartil_pobreza) ) +geom_area(position ='stack') +# innovar::scale_fill_innova("jama") +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#DAE2BC", "#8C3A33") ) +scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +labs(y =NULL,x =NULL,title ="Monthly mortality COVID-19 under 18 years old",fill ="Poverty Quartiles" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =as.Date("2023-07-01"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"),y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() ) mort_pobr_area_plot
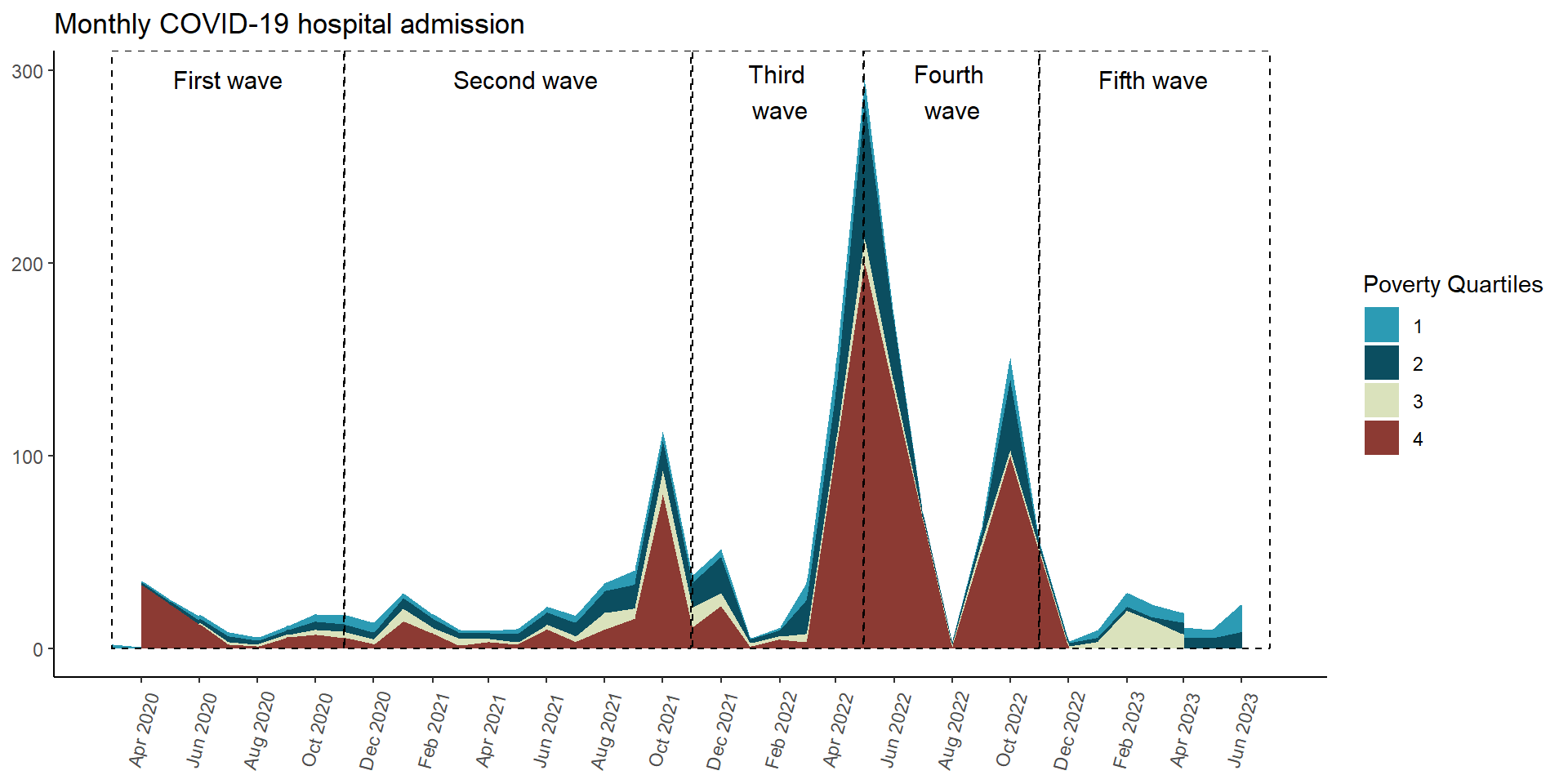
Figura 27: Mortalidad COVID-19 de acuerdo al cuartil de pobreza(14-03-2020 a 13-06-2023)
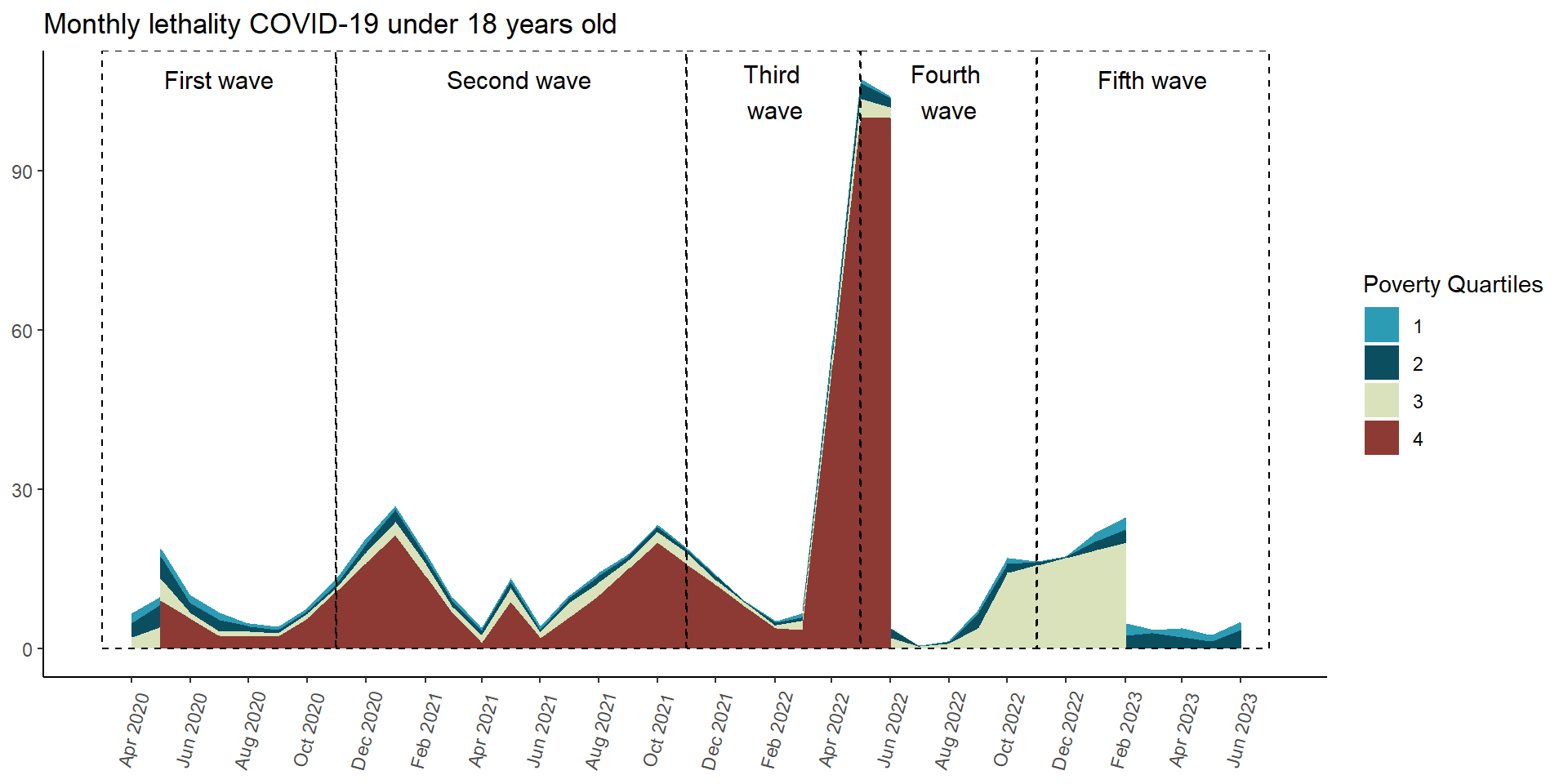
In [193]:
letal_pobr_area_plot <- results_per_month_letalidad$cuartil_pobreza$index %>%drop_na() %>%mutate(time =make_date(anio, mes, "1") ) %>%filter( time >ymd("2020-03-01") ) |>ggplot(aes(x = time,y = rate,fill = cuartil_pobreza) ) +geom_area(position ='stack') +# innovar::scale_fill_innova("jama") +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#DAE2BC", "#8C3A33") ) +scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +labs(y =NULL,x =NULL,title ="Monthly lethality COVID-19 under 18 years old",fill ="Poverty Quartiles" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =as.Date("2023-07-01"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"),y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() ) letal_pobr_area_plot
Letalidad COVID-19 de acuerdo al cuartil de pobreza(14-03-2020 a 13-06-2023)
Distrito Lima
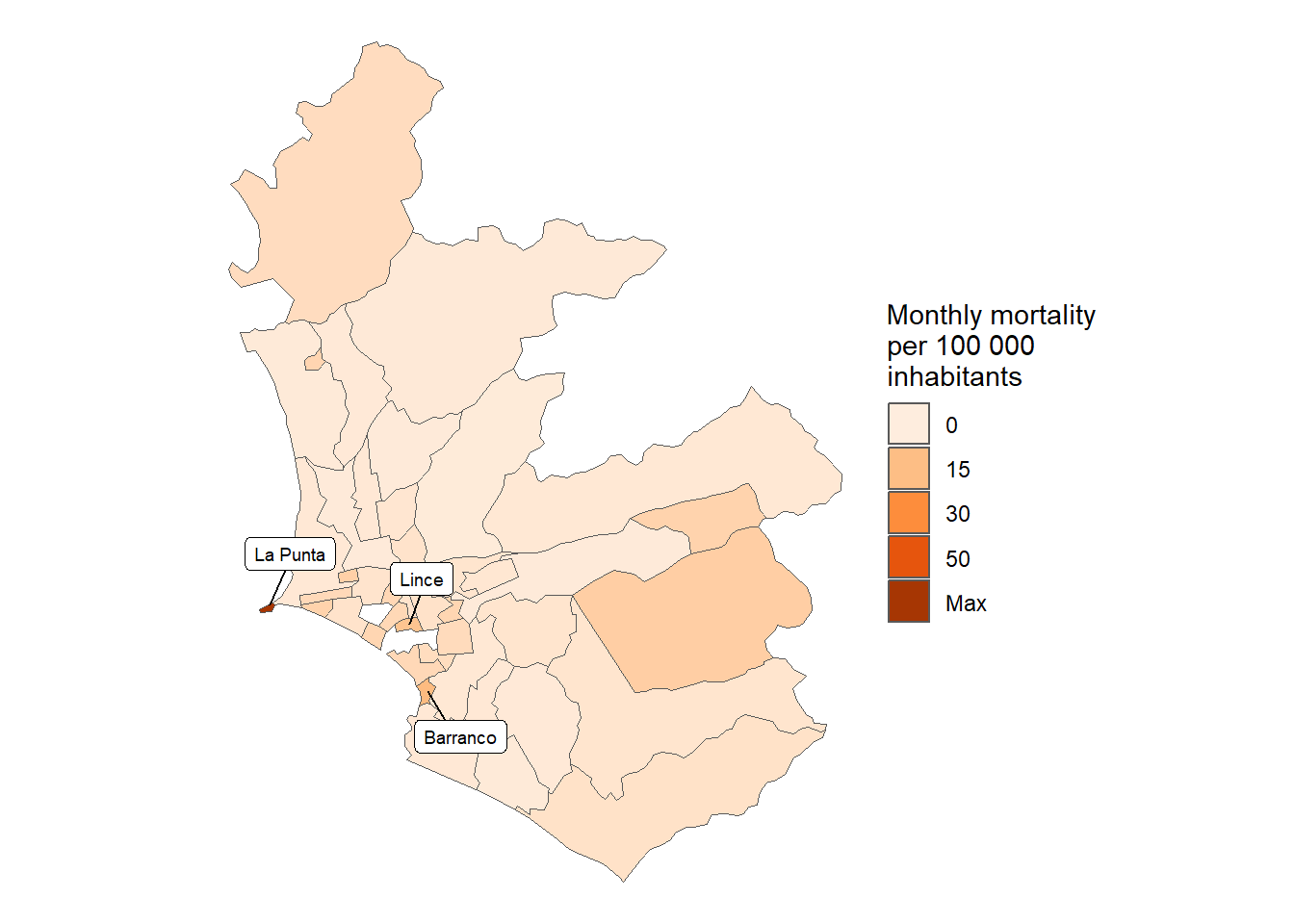
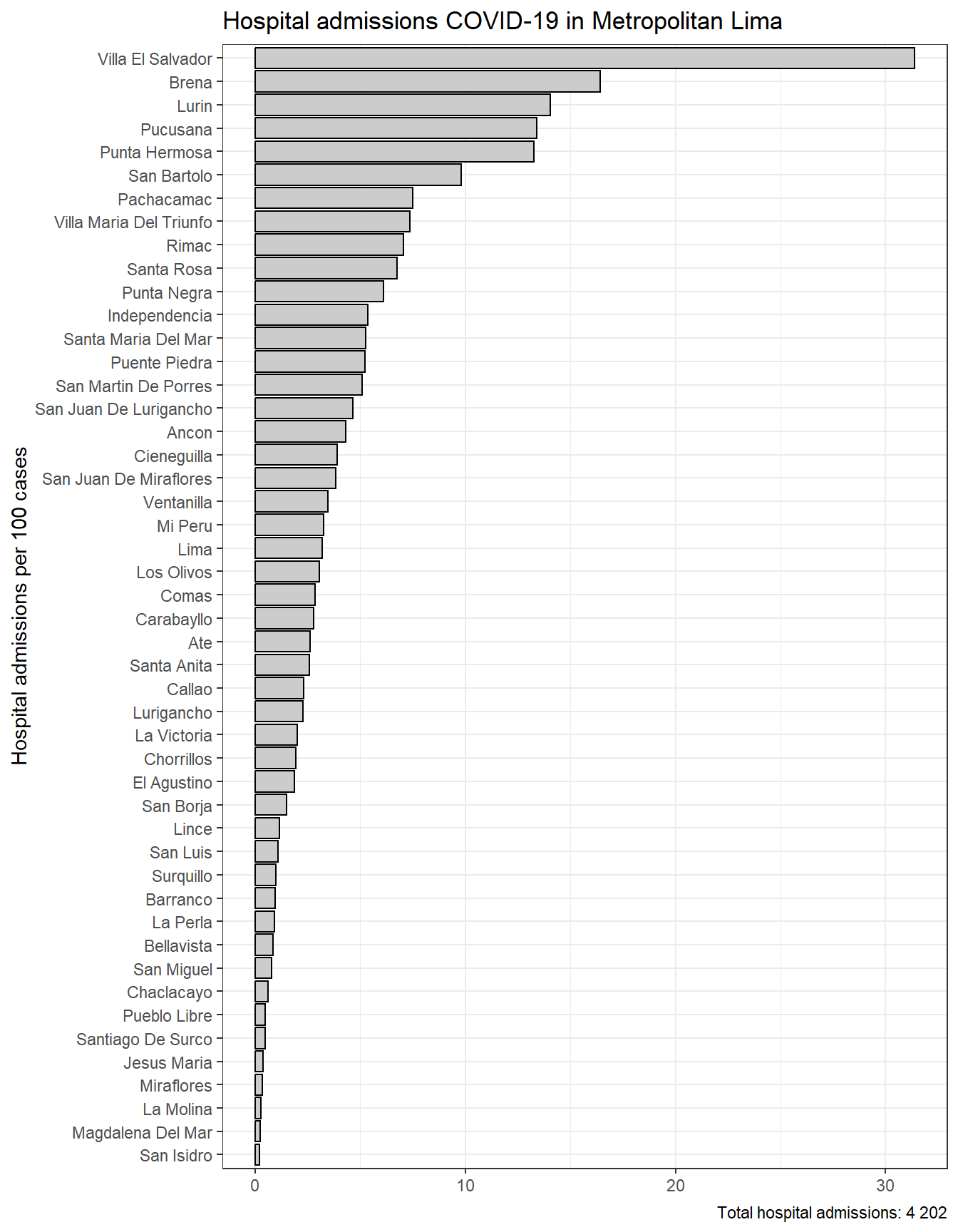
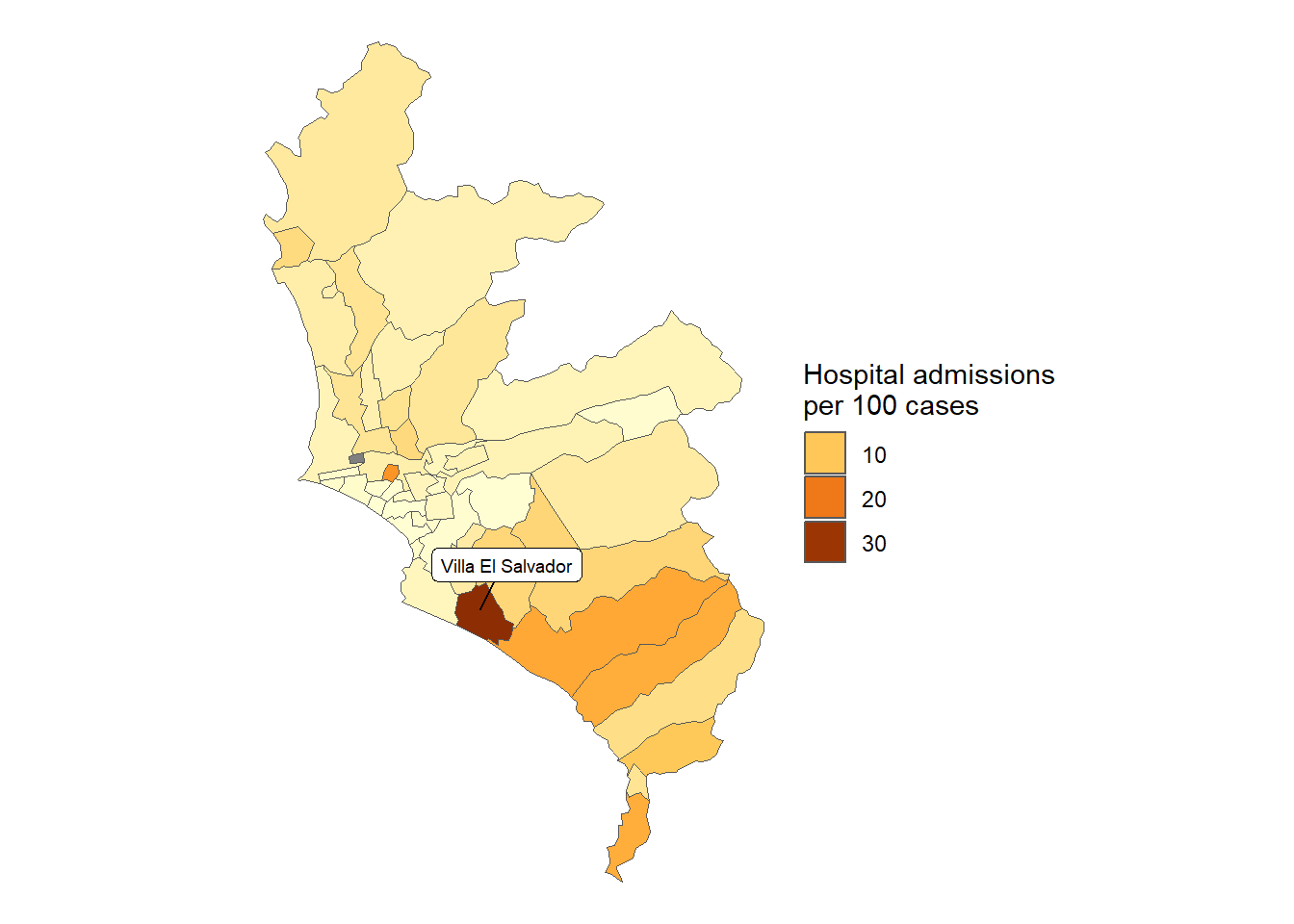
In [194]:
total_mort_distr_lim_callao <- results_mortalidad$distrito$index_pre %>%filter(provincia %in%c("LIMA", "CALLAO")) %>%pull(count) %>%sum()results_mortalidad$distrito$index %>%filter(provincia %in%c("LIMA", "CALLAO")) %>%mutate(distrito =str_to_title(distrito), distrito =fct_reorder(distrito, rate) ) %>%ggplot(aes(y = distrito, x = rate)) +geom_bar(stat ="identity",color ="black",fill ="grey80") +theme_bw() +labs(title ="Mortality COVID-19 in Metropolitan Lima", x =NULL, y ="Mean monthly COVID-19 mortality per 100 000 inhabitants",caption =paste0("Total deaths reported: ", scales::number(total_mort_distr_lim_callao))) + innovar::scale_fill_innova("blue_fall") +theme(legend.position ="bottom" )
Figura 28: Mortalidad COVID-19 de acuerdo a los distritos de lima metropolitana (14-03-2020 a 13-06-2023)
In [195]:
mort_lima_distr_1k_sf <- Peru %>%inner_join( results_mortalidad$distrito$index %>%filter(provincia %in%c("LIMA", "CALLAO")) )
downloadthis::download_file(path ="02_output/tables/mortalidad_lima_distrito.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [201]:
downloadthis::download_file(path ="02_output/tables/mortalidad_lima_distrito.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
Los datos utilizados para incidencia positivos tienen datos hasta julio de 2023. Se tiene registro de 315 046 casos positivos menores de 18 años. Para poder analizar la incidencia necesitamos saber que si un caso positivos es nuevo o es una reinfección que no se puede considerar aún como caso nuevo. Se tendrá como criterio 3 meses de espacio entre infecciones. Lamentablemente, incluso en estos datos, hay 12 495 registros sin id_persona.
Criterios para casos positivos y de reinfección:
Hasta 1 mes (30 días), se considera una misma infección.
Espacio de 3 meses a más (90 días), se considera una nueva infección (reinfección)
Reportar cantidad de casos que se encuentren entre 1 mes y menos de 3 meses (entre día 31 y 89), con su respectivo método.
In [204]:
incidencia_positivos %>%count(caso_intermedio)
# Source: SQL [?? x 2]
# Database: DuckDB v1.2.0 [brian@Windows 10 x64:R 4.4.2/D:\Github\covid-analisis-ninos\01_data\raw\covid.duckdb]
caso_intermedio n
<lgl> <dbl>
1 FALSE 302236
2 TRUE 245
3 NA 12565
downloadthis::download_file(path ="02_output/tables/hospitalizacion_descriptivos.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [213]:
downloadthis::download_file(path ="02_output/tables/hospitalizacion_descriptivos.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
In [214]:
hospital_comparisons <-compare_levels_per_month(results_per_month = results_per_month_hospi,levels = comparing_levels)# Extraer las tablas `cld` como tibbles, renombrando y añadiendo una columna "level"hospital_comparisons_cld_pre <-lapply(names(hospital_comparisons), function(level) { cld <- hospital_comparisons[[level]]$cldif (!is.null(cld)) { cld <- cld |>as_tibble() |>rename(group =1) |># Renombra la primera columna a 'group'mutate(level = level) |># Añade una columna 'level' con el nombre de la listarelocate(level) } cld}) |>bind_rows()hospital_comparisons_cld_pre <- hospital_comparisons_cld_pre |>mutate(across(where(is.numeric),~ formattable::digits(.x, 3) ) )
downloadthis::download_file(path ="02_output/tables/hospital_comparacion_multiple.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [219]:
downloadthis::download_file(path ="02_output/tables/hospital_comparacion_multiple.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/hospitalizados_olas_descriptivos.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [224]:
downloadthis::download_file(path ="02_output/tables/hospitalizados_olas_descriptivos.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
Gráfico de hospitalización (serie de tiempo) - Menores de 18 años
In [225]:
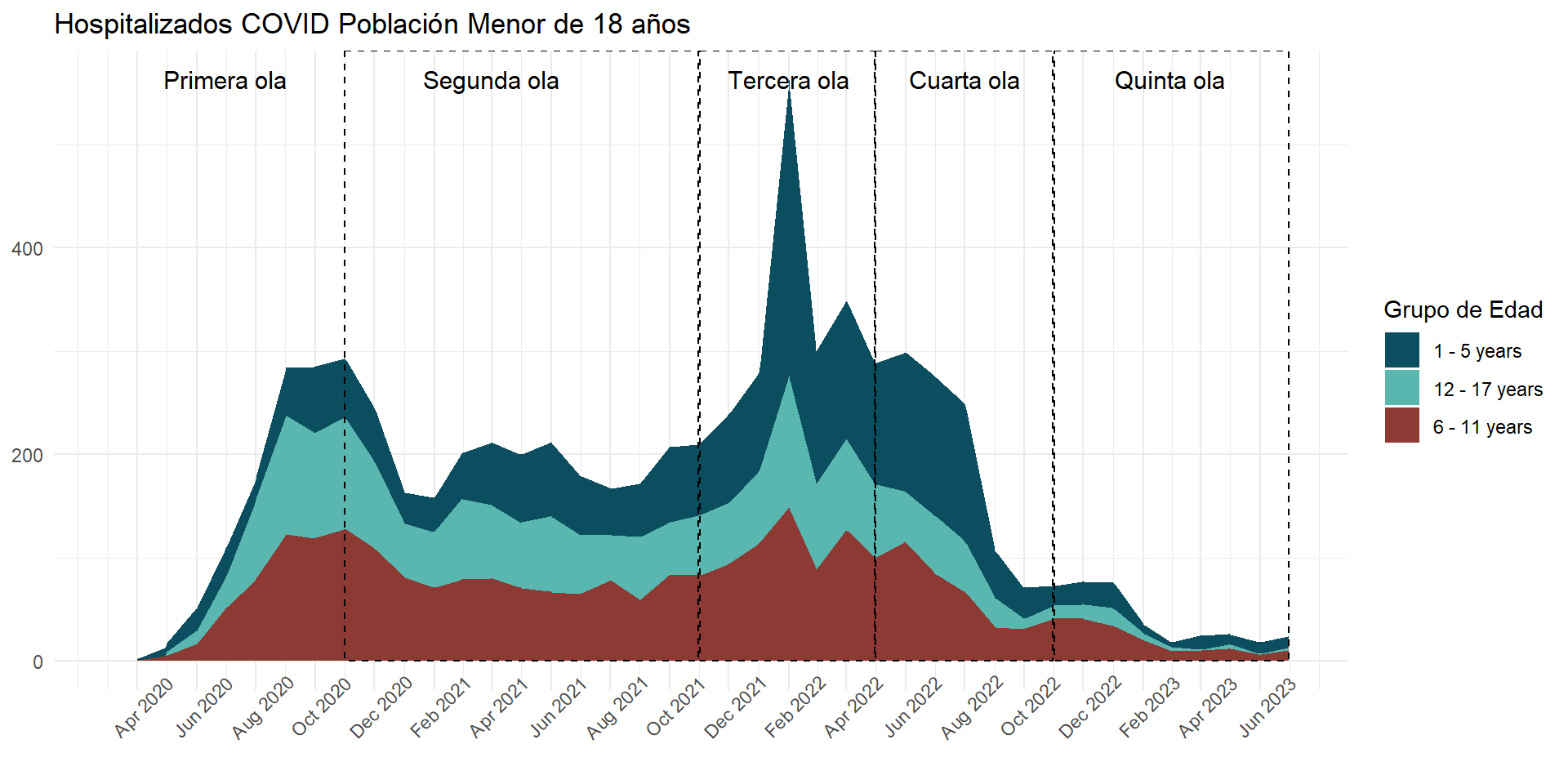
hospi_count_by_age_area <- hospitalizados %>%to_arrow() %>%mutate(fecha_round =ceiling_date(fecha_ingreso_hosp, unit ="month") ) %>%compute() %>%to_duckdb() %>%mutate(fecha_round =case_when( fecha_round ==as.Date("2024-01-01") ~as.Date("2023-12-31"),.default = fecha_round ) ) %>%count(grupo_edad, fecha_round) %>%collect()hospi_age_area_plot <- hospi_count_by_age_area %>%bind_rows(tibble(grupo_edad ="Under 1 year",fecha_round =seq(from =as.Date("2020-04-01"), to =as.Date("2023-07-01"), by ="month"),n =0 ) ) %>%mutate(grupo_edad =factor( grupo_edad,levels =c("Under 1 year", "1 - 5 years","6 - 11 years", "12 - 17 years") ) ) %>%ggplot(aes(x = fecha_round,y = n,fill = grupo_edad ) ) +geom_area(position ='stack') +# innovar::scale_fill_innova("jama") +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#DAE2BC", "#8C3A33") ) +scale_x_date(limits =c(ymd("2020-03-07"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-07"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +labs(y =NULL,x =NULL,title ="COVID-19 hospital admissions",fill ="Age Group" ) +annotate(geom ="rect",xmin =as.Date("2020-04-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-15"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =as.Date("2023-07-01"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"),y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() ) hospi_age_area_plot
Figura 30: Hospitalización COVID-19 de acuerdo a la edad y ola covid (24-03-2020 a 16-06-2023)
Gráfico Tasa de hospitalización (serie de tiempo)
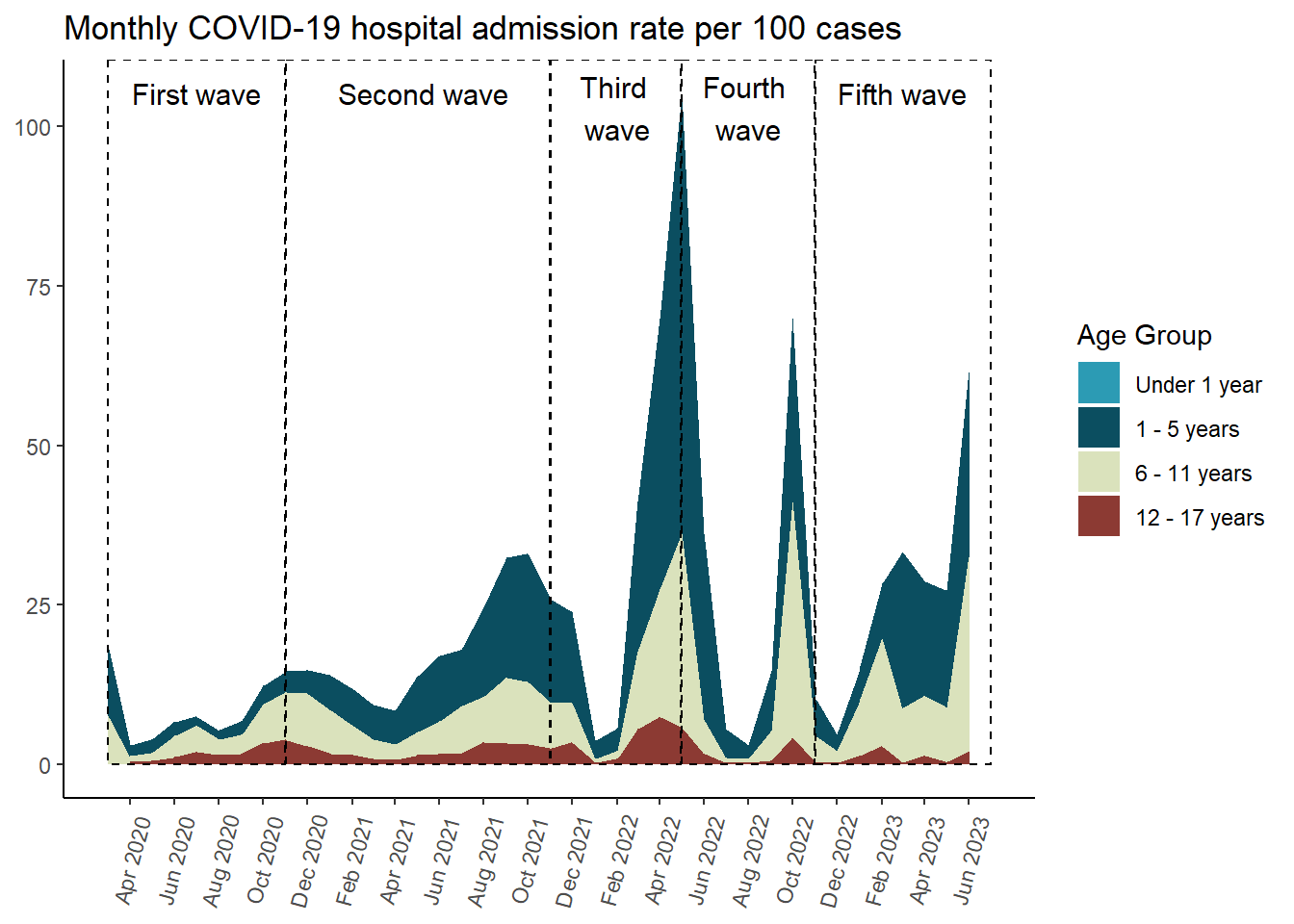
In [226]:
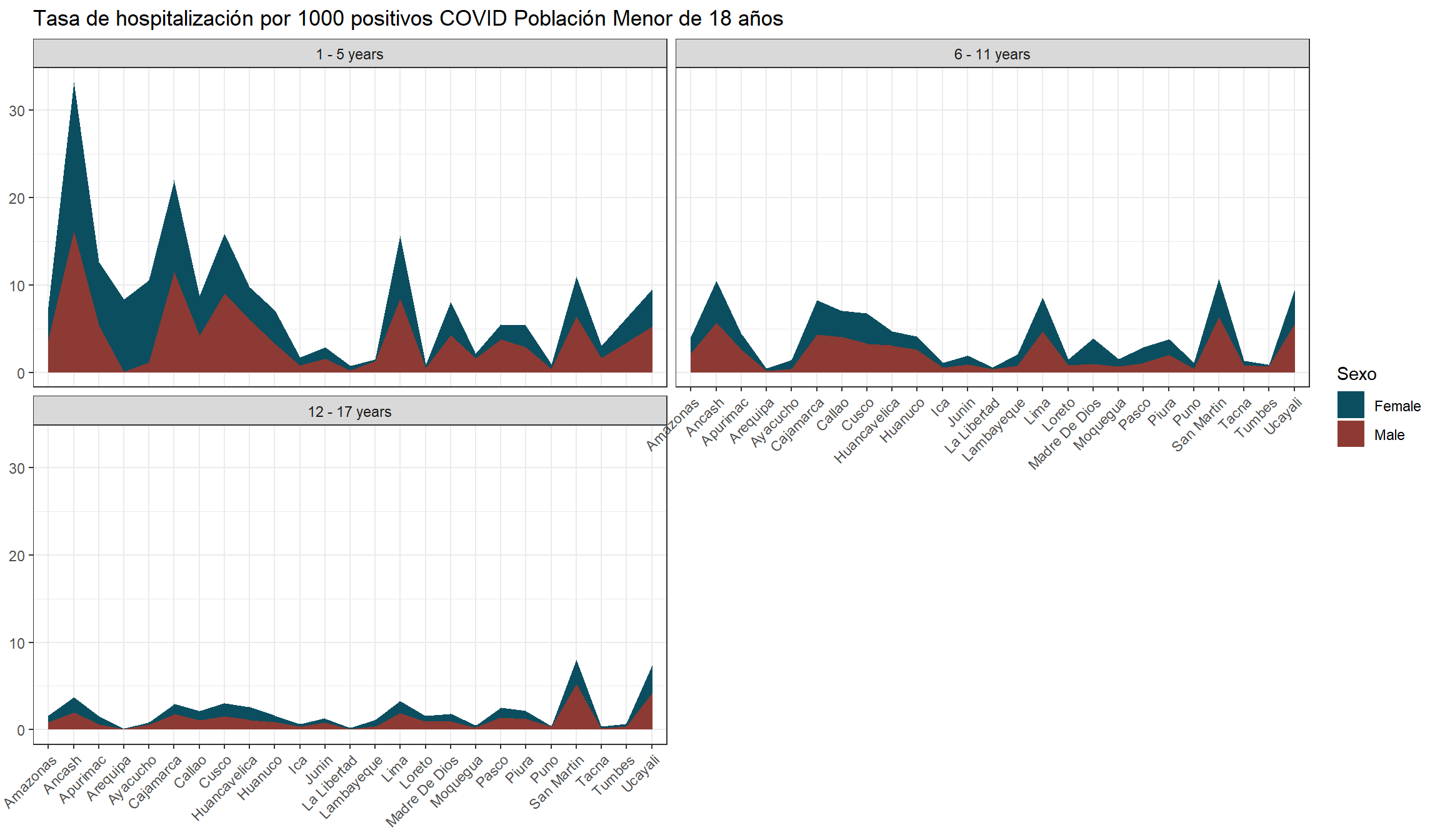
per_month_hospi_under_1 <-tibble(grupo_edad ="Under 1 year",time =seq(from =as.Date("2020-03-01"), to =as.Date("2023-07-01"), by ="month"),rate =0)hospi_rate_by_age_area <- results_per_month_hospi$grupo_edad$index %>%mutate(time =make_date(anio, mes, "1") ) %>%bind_rows( per_month_hospi_under_1 ) %>%mutate(grupo_edad =factor( grupo_edad,levels =c("Under 1 year", "1 - 5 years","6 - 11 years", "12 - 17 years") ) ) %>%ggplot(aes(x = time,y = rate,fill = grupo_edad ) ) +geom_area(position ='stack') +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#DAE2BC", "#8C3A33") ) +scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +labs(y =NULL,x =NULL,title ="Monthly COVID-19 hospital admission rate per 100 cases",fill ="Age Group" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =as.Date("2023-07-01"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"),y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() ) hospi_rate_by_age_area
downloadthis::download_file(path ="02_output/tables/tasa_hospitalizacion_departamento.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [238]:
downloadthis::download_file(path ="02_output/tables/tasa_hospitalizacion_departamento.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
Warning in st_point_on_surface.sfc(data$geometry): st_point_on_surface may not
give correct results for longitude/latitude data
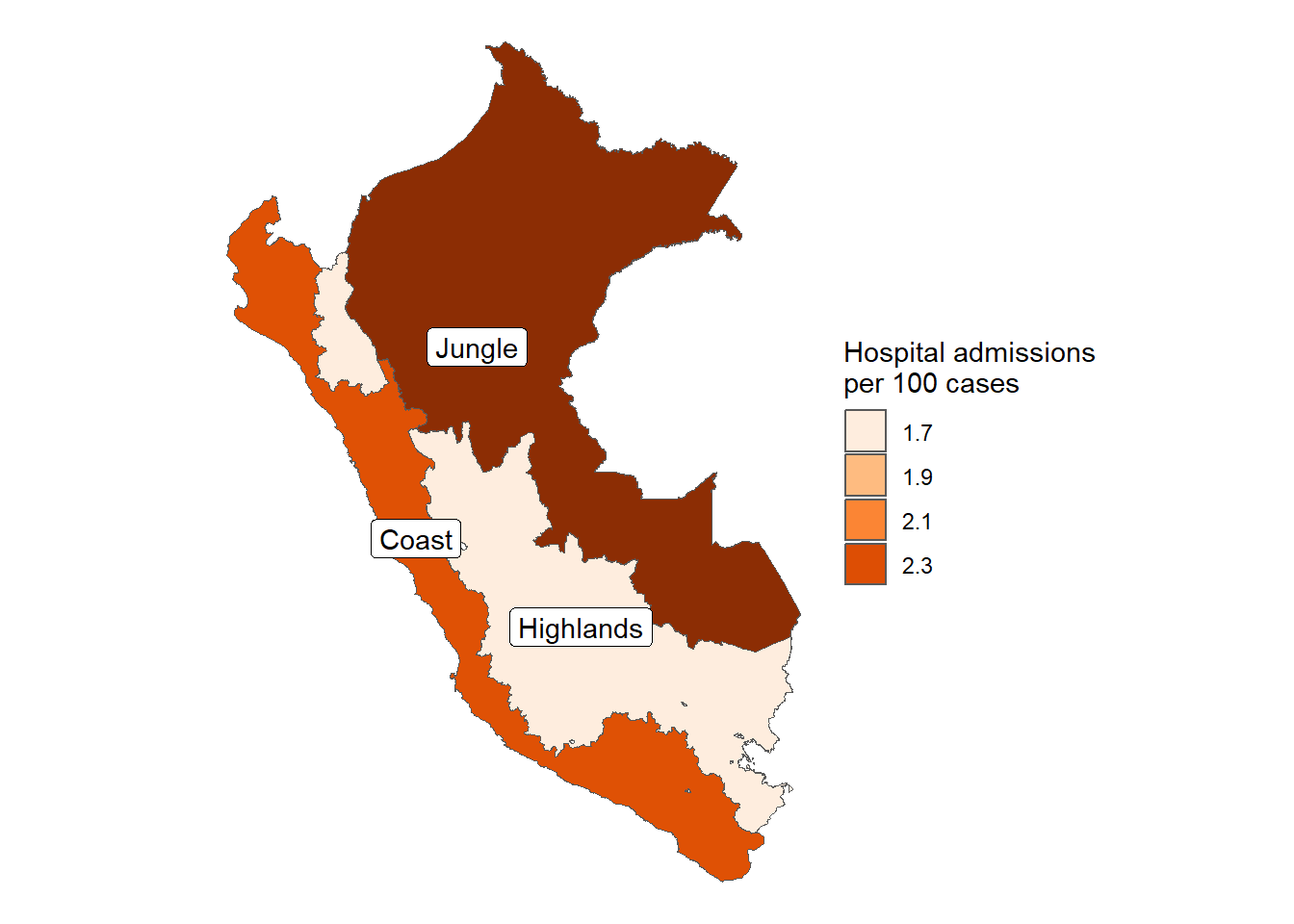
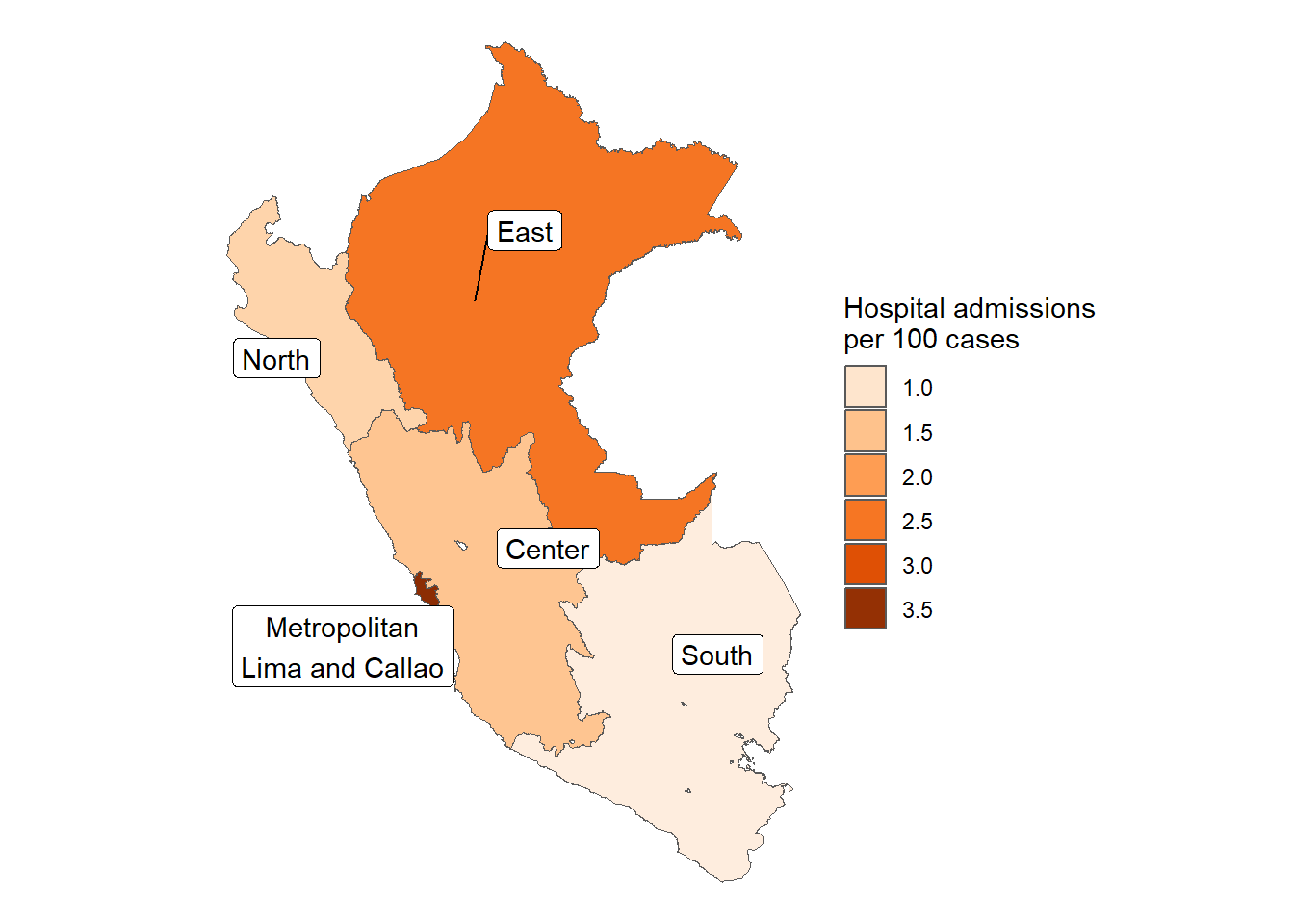
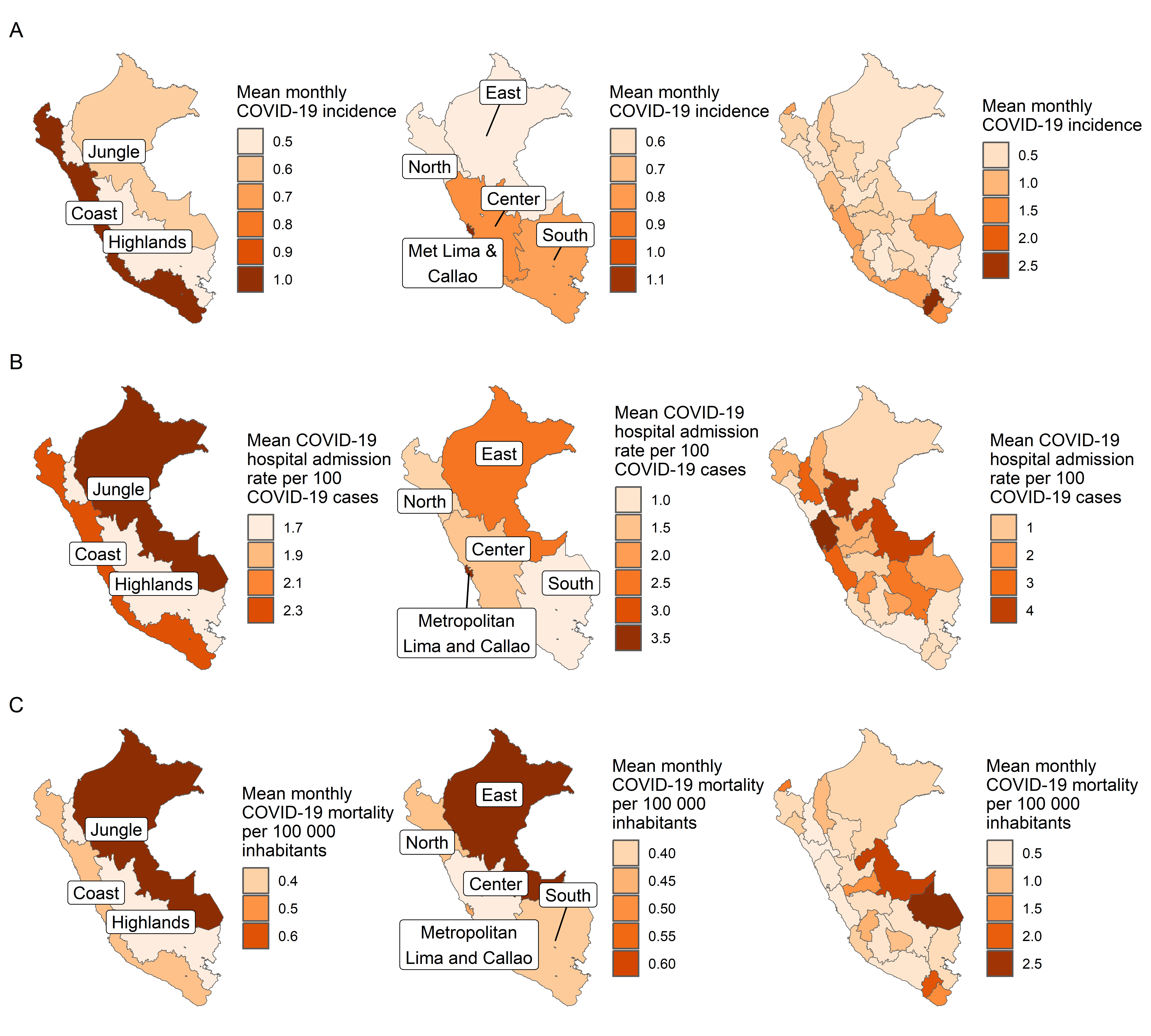
Figura 38: Tasa de Hospitalización por 1000 positivos COVID-19 de acuerdo a la macrorregión (24-03-2020 a 16-06-2023)
Distrital y pobreza
In [250]:
hospi_pobr_area_plot <- results_per_month_hospi$cuartil_pobreza$index %>%drop_na() %>%mutate(time =make_date(anio, mes, "1") ) %>%ggplot(aes(x = time,y = rate,fill = cuartil_pobreza) ) +geom_area(position ='stack') +# innovar::scale_fill_innova("jama") +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#DAE2BC", "#8C3A33") ) +scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +labs(y =NULL,x =NULL,title ="Monthly COVID-19 hospital admission",fill ="Poverty Quartiles" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =as.Date("2023-07-01"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"),y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() ) hospi_pobr_area_plot
Figura 39: Mortalidad COVID-19 de acuerdo al cuartil de pobreza(14-03-2020 a 13-06-2023)
Distrito Lima
In [251]:
total_hospi_distr_lim_callao <- results_hospi$distrito$index_pre %>%filter(provincia %in%c("LIMA", "CALLAO")) %>%pull(count) %>%sum()results_hospi$distrito$index %>%filter(provincia %in%c("LIMA", "CALLAO")) %>%drop_na() %>%mutate(distrito =str_to_title(distrito), distrito =fct_reorder(distrito, rate) ) %>%ggplot(aes(y = distrito, x = rate)) +geom_bar(stat ="identity",color ="black",fill ="grey80") +theme_bw() +labs(title ="Hospital admissions COVID-19 in Metropolitan Lima", x =NULL, y ="Mean COVID-19 hospital admission rate per 100 COVID-19 cases",caption =paste0("Total hospital admissions: ", scales::number(total_hospi_distr_lim_callao))) + innovar::scale_fill_innova("blue_fall") +theme(legend.position ="bottom" )
Figura 40: Tasa de Hospitalización COVID-19 de acuerdo a los distritos de lima metropolitana (24-03-2020 a 16-06-2023)
In [252]:
tasa_hospi_lima_distr_1k_sf <- Peru %>%inner_join( results_hospi$distrito$index %>%filter(provincia %in%c("LIMA", "CALLAO")) )
downloadthis::download_file(path ="02_output/tables/tasa_hospitalizacion_lima_distrito.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [258]:
downloadthis::download_file(path ="02_output/tables/tasa_hospitalizacion_lima_distrito.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/vacunas_descriptivos.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [266]:
downloadthis::download_file(path ="02_output/tables/vacunas_descriptivos.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
In [267]:
comparing_levels <-list(c("grupo_edad"),c("sexo"),c("ola_covid"),c("cuartil_pobreza"),c("cuartil_nbi"),c("region"),c("macrorregion"))vacunas_comparisons <-compare_levels_per_month(results_per_month = results__per_month_vacunas,levels = comparing_levels)# Extraer las tablas `cld` como tibbles, renombrando y añadiendo una columna "level"vacunas_comparisons_cld_pre <-lapply(names(vacunas_comparisons), function(level) { cld <- vacunas_comparisons[[level]]$cldif (!is.null(cld)) { cld <- cld |>as_tibble() |>rename(group =1) |># Renombra la primera columna a 'group'mutate(level = level) |># Añade una columna 'level' con el nombre de la listarelocate(level) } cld}) |>bind_rows()vacunas_comparisons_cld_pre <- vacunas_comparisons_cld_pre |>mutate(across(where(is.numeric),~ formattable::digits(.x, 3) ) )
downloadthis::download_file(path ="02_output/tables/vacunas_comparacion_multiple.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [272]:
downloadthis::download_file(path ="02_output/tables/vacunas_comparacion_multiple.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
downloadthis::download_file(path ="02_output/tables/fallecidos_olas_descriptivos.xlsx",button_label ="Descargar tabla en Excel",button_type ="success",has_icon =TRUE,icon ="fa fa-save")
In [277]:
downloadthis::download_file(path ="02_output/tables/fallecidos_olas_descriptivos.docx",button_label ="Descargar tabla en Word",button_type ="primary",has_icon =TRUE,icon ="fa fa-save")
Gráfico de vacunación (serie de tiempo) - Menores de 18 años
Se restringió la visualización de dosis de 1 a 5.
In [278]:
summ_vacunas_dosis_fecha <- vacunas_18 %>%to_arrow() %>%mutate(fecha_round =ceiling_date(fecha_vacunacion, unit ="month"),.after = fecha_vacunacion ) %>%# filter(dosis %in% 1:5) %>% count(dosis, fecha_round) %>%collect()summ_vacunas_dosis_fecha %>%ggplot(aes(x = fecha_round,y = n,fill =as.factor(dosis) ) ) +geom_area(position ='stack') +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#8C3A33") ) +# scale_x_date(# limits = c(ymd("2020-03-01"), ymd("2023-10-31")),# breaks = scales::date_breaks("2 month"), # Cambiar a "6 months" para menos frecuencia# labels = scales::date_format("%b %Y") # Formato de fecha, %b es la abreviatura de mes, %Y es el año# ) + scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +scale_y_continuous(labels = scales::number_format() ) +labs(y =NULL,x =NULL,title ="Vaccination COVID-19 under 18 years old",fill ="Doses" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =dmy(range_vacu$max), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() )
Figura 42: Vacunación COVID Población menor de edad de acuerdo a la dosis y ola (03-01-2021 a 17-06-2023)
Gráfico de vacunación (serie de tiempo) - Grupo Etáreo
In [279]:
summ_vacunas_edad_fecha <- vacunas_18 %>%to_arrow() %>%mutate(fecha_round =ceiling_date(fecha_vacunacion, unit ="month"),.after = fecha_vacunacion ) %>%count(grupo_edad, fecha_round) %>%collect() summ_vacunas_edad_fecha %>%ggplot(aes(x = fecha_round,y = n,fill = grupo_edad ) ) +geom_area(position ='stack') +scale_fill_manual(values =c("#2C9BB4", "#0B4E60", "#DAE2BC", "#8C3A33") ) +# scale_x_date(# limits = c(ymd("2020-03-01"), ymd("2023-10-31")),# breaks = scales::date_breaks("2 month"), # Cambiar a "6 months" para menos frecuencia# labels = scales::date_format("%b %Y") # Formato de fecha, %b es la abreviatura de mes, %Y es el año# ) + scale_x_date(limits =c(ymd("2020-03-01"), ymd("2023-07-01")),breaks =seq(from =ceiling_date(ymd("2020-03-01"), "month"),to =floor_date(ymd("2023-07-01"), "month"),by ="2 months"), # date_breaks = "2 month",date_labels ="%b %Y" ) +scale_y_continuous(labels = scales::number_format() ) +labs(y =NULL,x =NULL,title ="Vaccination COVID-19 under 18 years old",fill ="Age Group" ) +annotate(geom ="rect",xmin =as.Date("2020-03-01"), xmax =as.Date("2020-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2020-07-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="First wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2020-11-01"), xmax =as.Date("2021-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2021-05-10"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Second wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2021-11-01"), xmax =as.Date("2022-04-30"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-02-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Third \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-05-01"), xmax =as.Date("2022-10-31"), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2022-08-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fourth \nwave", color ="black",size =4, # Tamaño del textovjust =1.25# Ajuste vertical para colocar el texto encima del rectángulo ) +annotate(geom ="rect",xmin =as.Date("2022-11-01"), xmax =dmy(range_vacu$max), ymin =0, # El rectángulo se extiende hasta la parte inferior del gráficoymax =Inf, # El rectángulo se extiende hasta la parte superior del gráficocolor ="black", # Color de la líneafill =NA, # Sin rellenolinetype ="dashed", # Tipo de línea discontinualinewidth =0.5# Grosor de la línea ) +annotate(geom ="text", x =as.Date("2023-03-01"), # Punto medio aproximado de la Ola 2y =Inf, # Posición vertical del textolabel ="Fifth wave", color ="black",size =4, # Tamaño del textovjust =2# Ajuste vertical para colocar el texto encima del rectángulo ) +theme_classic() +theme(axis.text.x =element_text(angle =75,vjust =0.5 ),axis.ticks.x =element_line() )
Figura 43: Vacunación COVID Población menor de edad de acuerdo al grupo etáreo y ola (03-01-2021 a 17-06-2023)
Pirámide frecuencia - Edades
In [280]:
library(patchwork)
Adjuntando el paquete: 'patchwork'
The following object is masked from 'package:cowplot':
align_plots
create_age_pyramids <-function(data, age, by, proportional =FALSE, scale_adjust =7, angle.axis =NULL) { plots <-list()for (dosis in1:3) {# Filtra por dosis y crea el gráfico p <- data %>%filter(dosis == dosis) %>%age_pyramid(age_group =!!rlang::enquo(age), split_by =!!rlang::enquo(by),proportional = proportional) +scale_fill_brewer(palette ="Dark2") +labs(subtitle =paste("Dosis", dosis),x =NULL,fill ="Sexo",y =NULL ) +theme_classic() +theme(axis.text.x =element_text(angle = angle.axis,vjust =0.5,hjust =0.5 ) )if (!proportional) { p <- p +scale_y_continuous(labels =~ scales::number(abs(.x)),n.breaks = scale_adjust ) }if (dosis %in%1:2) { p <- p +theme(axis.text.x =element_blank(),axis.ticks.x =element_blank() ) } plots[[dosis]] <- p }# Combina todos los gráficos en uno solo usando patchwork combined_plot <-reduce(plots, `+`) +plot_layout(guides ='collect') &labs(x ="Edad", y ="Frecuencia") +theme(legend.position ='bottom')return(combined_plot)}
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
In [282]:
vacunas_18_descr_tbl %>%create_age_pyramids(age = grupo_edad, by = sexo, scale_adjust =6,angle.axis =20)
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
Scale for fill is already present.
Adding another scale for fill, which will replace the existing scale.
`summarise()` has grouped output by "macrorregion" and "grupo_edad". You can
override using the `.groups` argument.
`summarise()` has grouped output by "anio" and "macrorregion". You can override
using the `.groups` argument.
Warning in st_point_on_surface.sfc(data$geometry): st_point_on_surface may not
give correct results for longitude/latitude data
Warning in st_point_on_surface.sfc(data$geometry): st_point_on_surface may not
give correct results for longitude/latitude data
Warning in st_point_on_surface.sfc(data$geometry): st_point_on_surface may not
give correct results for longitude/latitude data
Warning in st_point_on_surface.sfc(data$geometry): st_point_on_surface may not
give correct results for longitude/latitude data
Warning in st_point_on_surface.sfc(data$geometry): st_point_on_surface may not
give correct results for longitude/latitude data
Warning in st_point_on_surface.sfc(data$geometry): st_point_on_surface may not
give correct results for longitude/latitude data
Warning in st_point_on_surface.sfc(data$geometry): st_point_on_surface may not
give correct results for longitude/latitude data
Warning in st_point_on_surface.sfc(data$geometry): st_point_on_surface may not
give correct results for longitude/latitude data
Warning in st_point_on_surface.sfc(data$geometry): st_point_on_surface may not
give correct results for longitude/latitude data
Warning in st_point_on_surface.sfc(data$geometry): st_point_on_surface may not
give correct results for longitude/latitude data